Hello community,
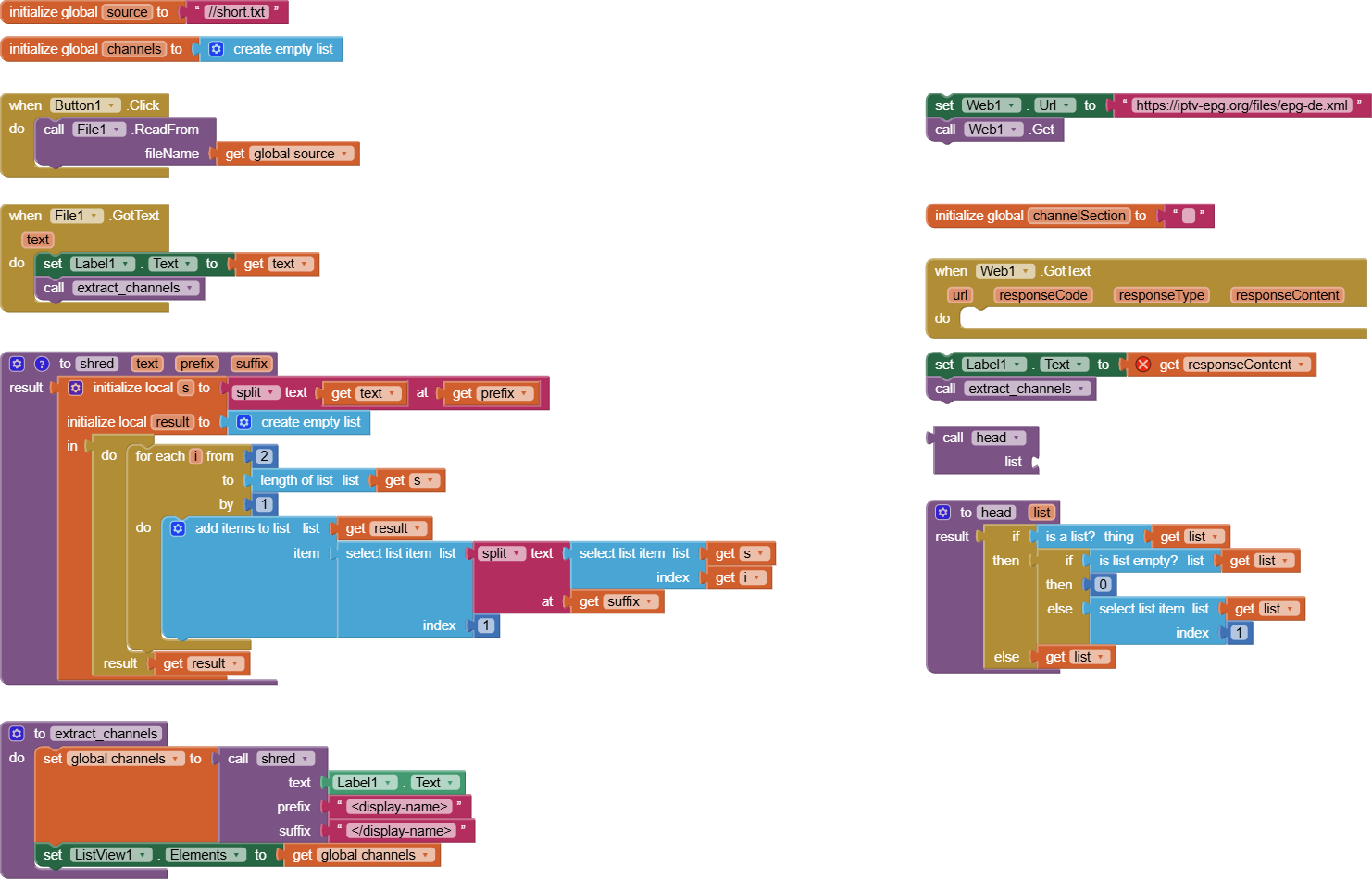
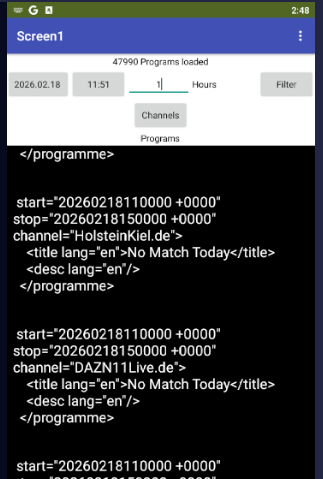
due to a bug in my epg app i started some research in web and randomly found that: guide, xml-data
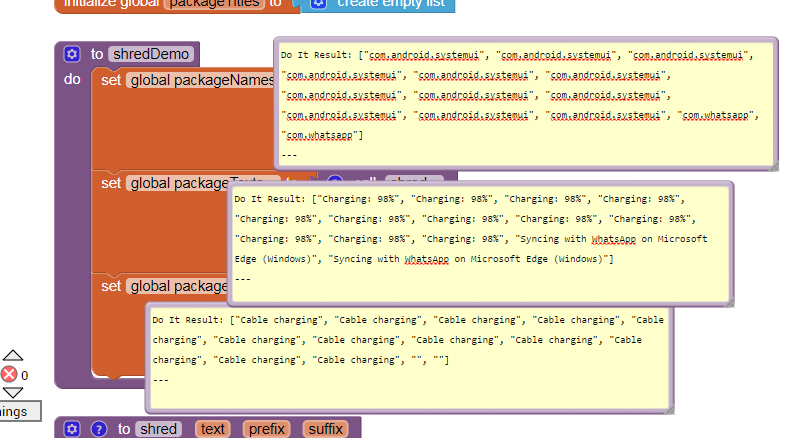
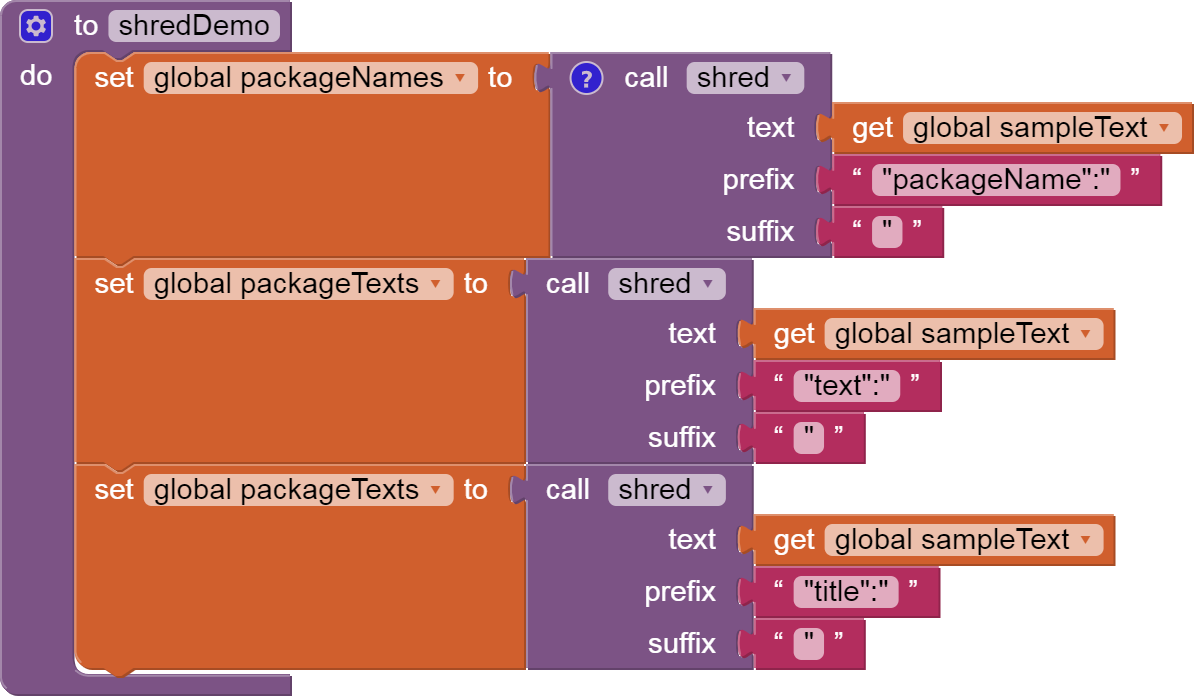
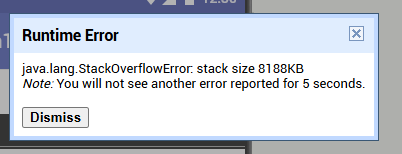
Loading that data and parsing it with web-component works one tine. than it leads to a low memory error.
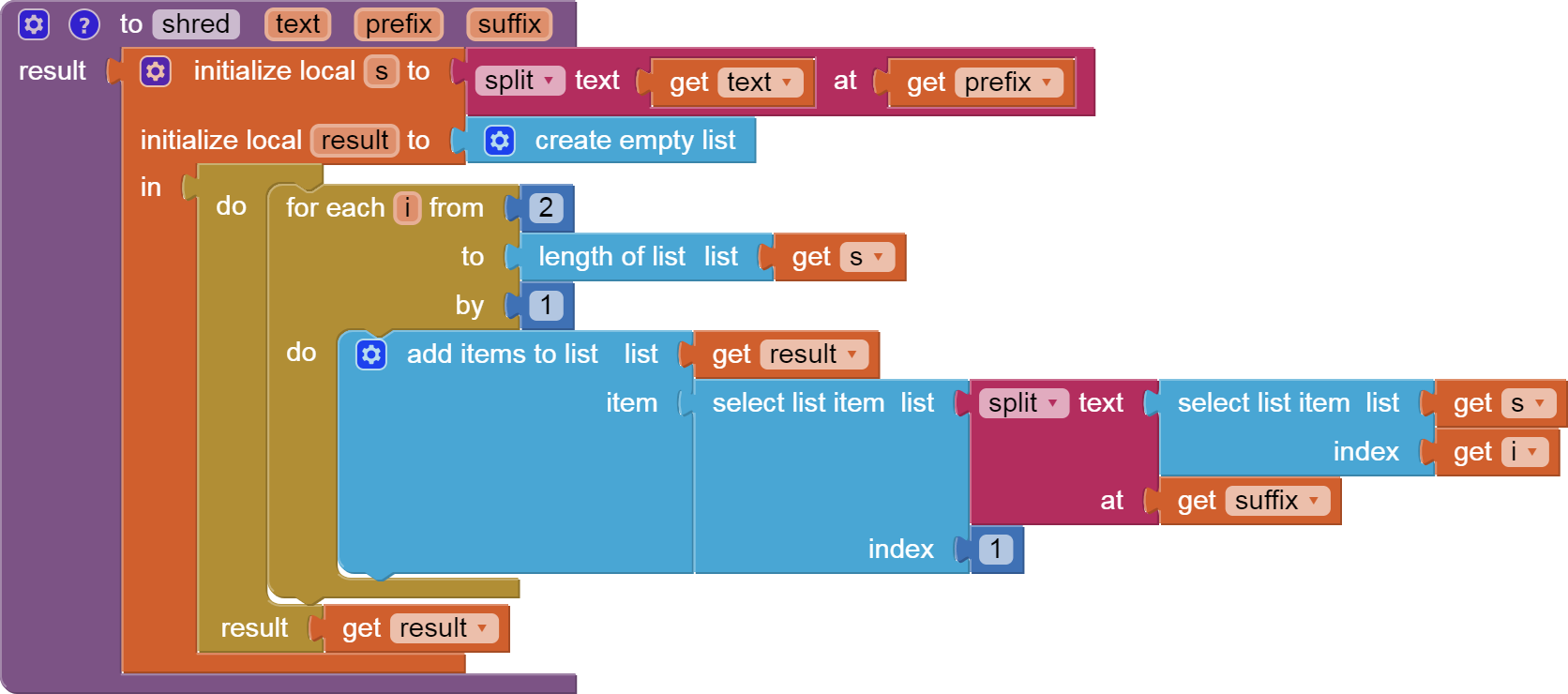
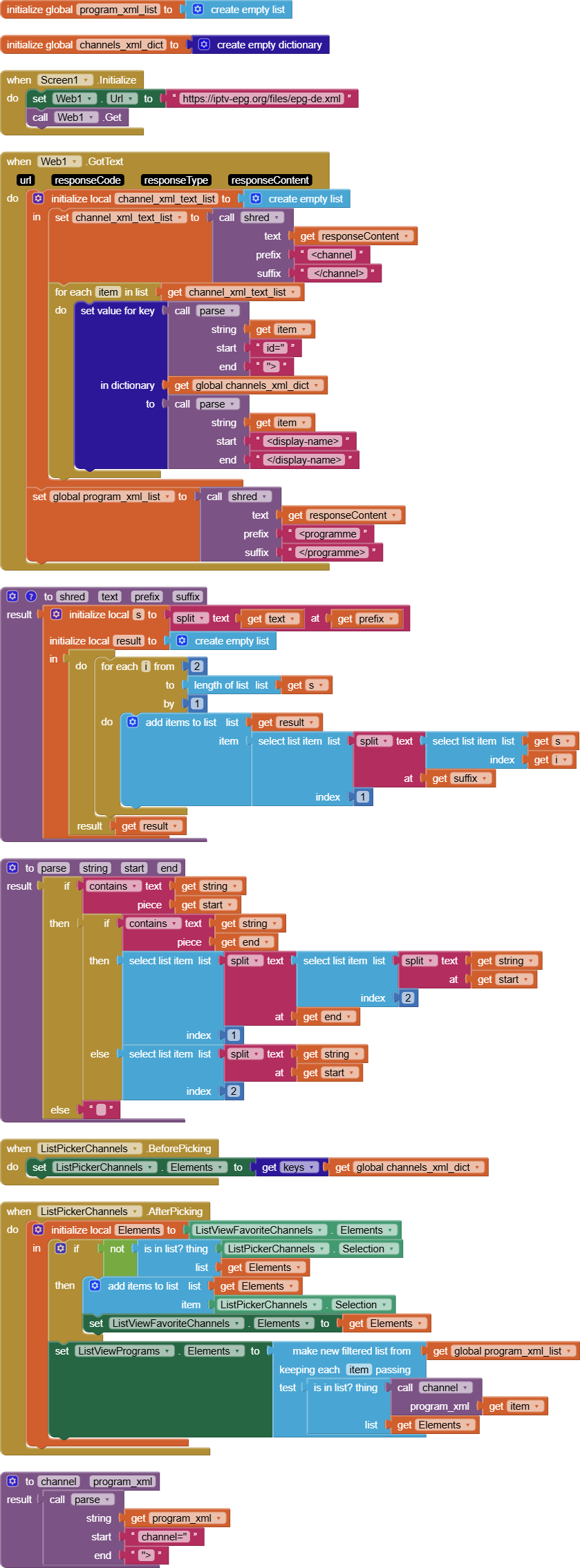
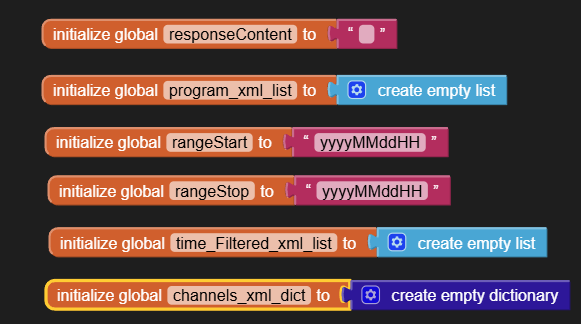
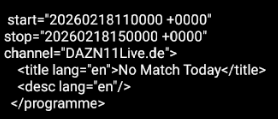
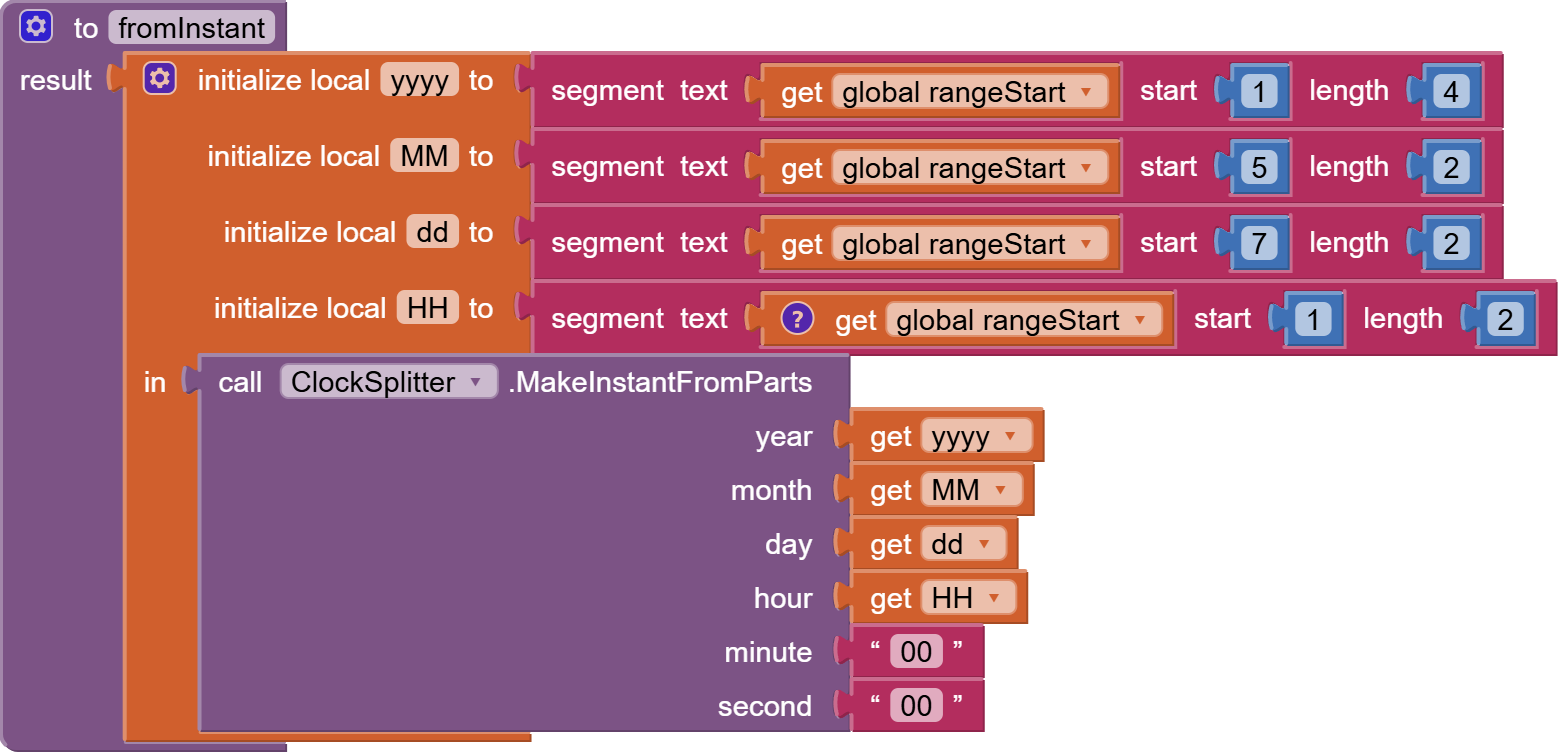
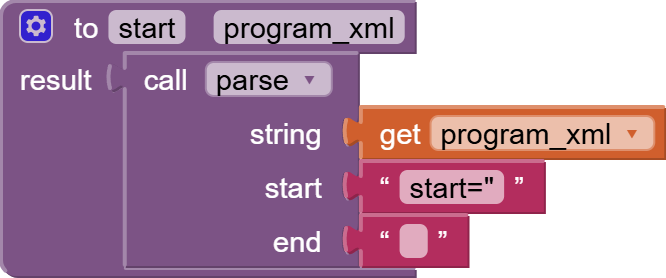
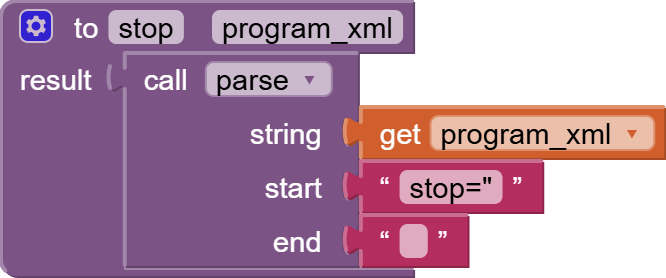
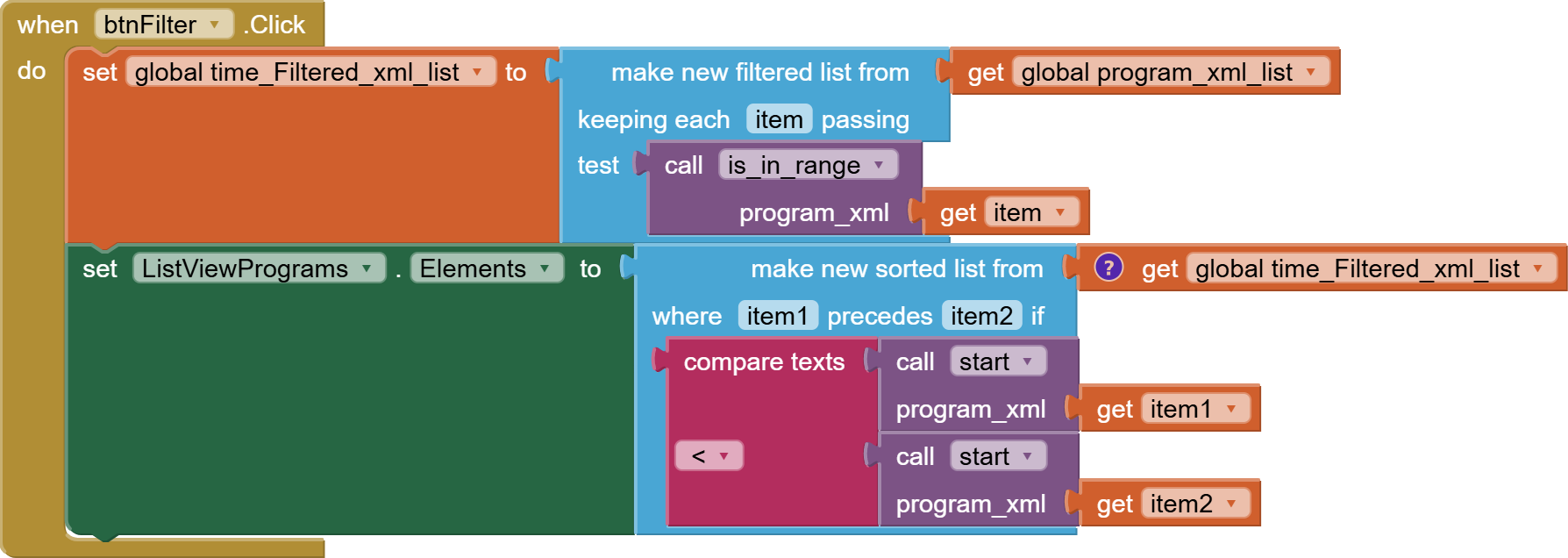
I found this: link 1 and that link 2. I do not realy understand the logic how can i access the deep structure in database which is created by XMLTextDecodeAsDictionary independently of the problem with the memory.
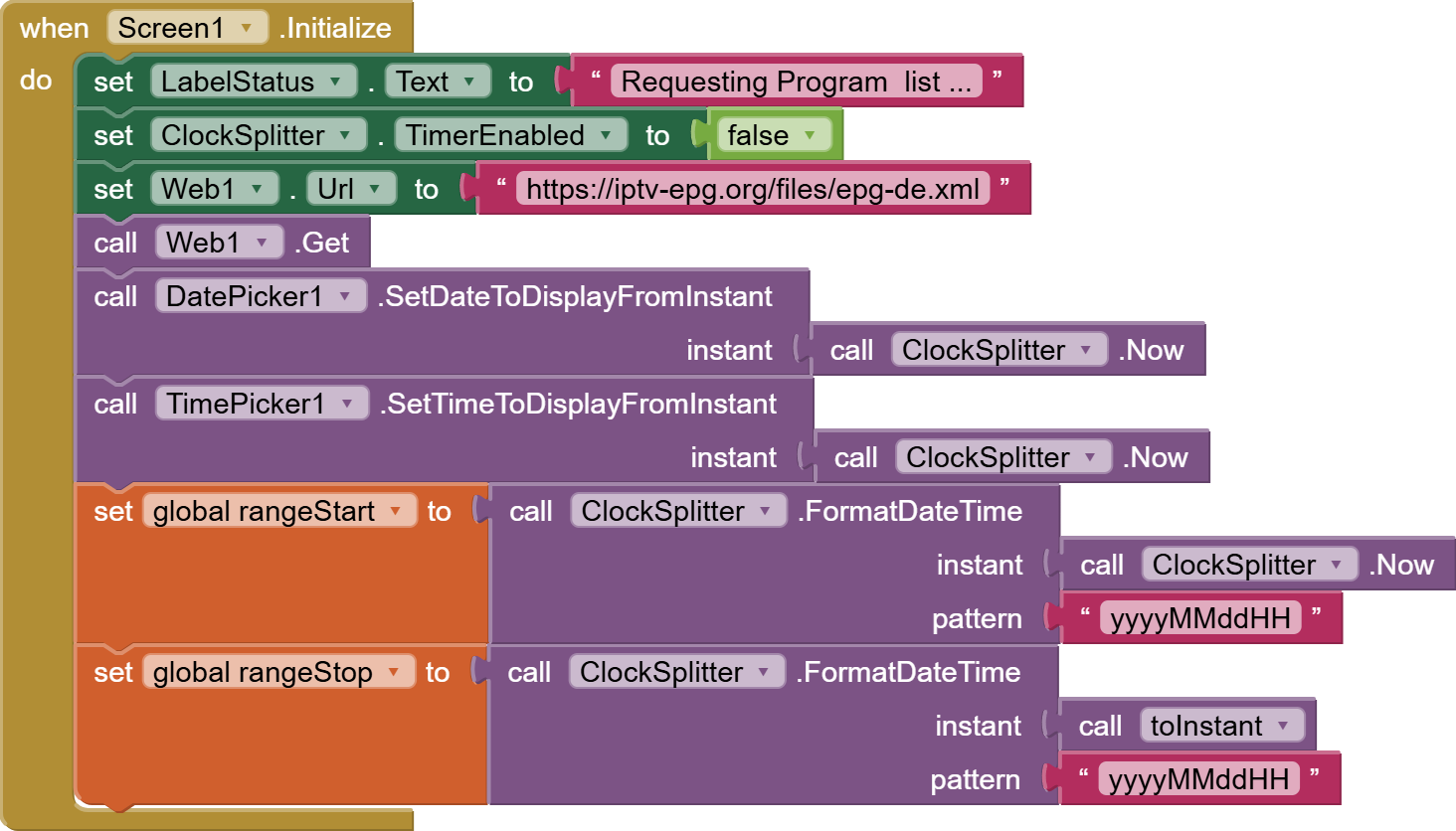
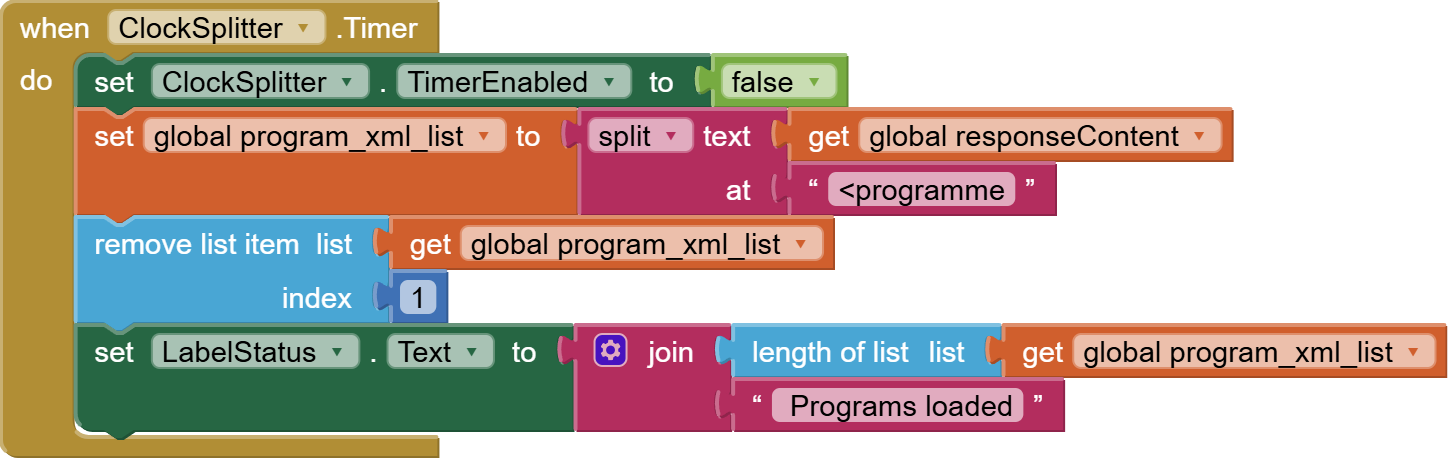
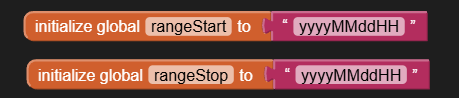
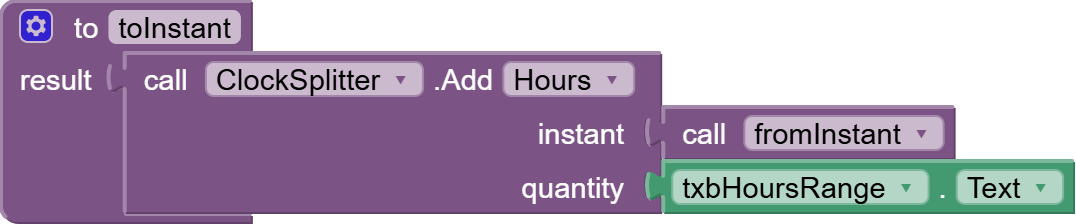
Now I am looking for a possibility to parse the responseContent from web.gotText manually. But I find no way how to do it. Is there any possibility to walk through the content searching a tag, remember the position and then continue searching from that position?
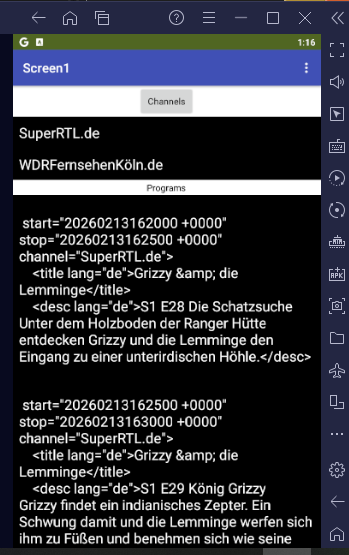
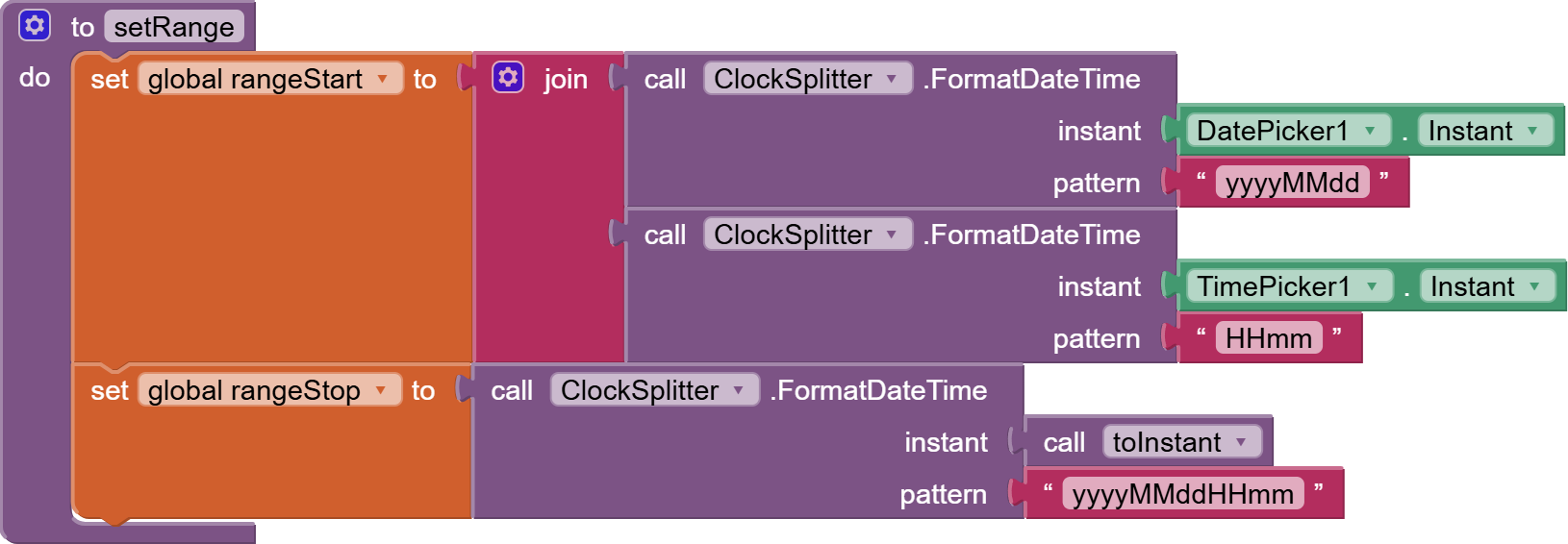
Did anybody was triing to build an epg app with mit app inventor or is it too much because of the amount of xml content? Are there other possibilities to realize? The purpose is not to built an IPTV app (I found a project, tried it out and it works) what I want is a channel list and the television program for a time range.
Thanks in advance for ideas, opinions and / or help