Good job ![]()
1 Like
Thanks, your extensions are also good as always
 New Update
New Update
Gemini extension now allows you to create and modify images via instructions using Google's Gemini AI models directly within your App Inventor projects!
New Update: You can now use the Gemini AI model to analyze any video, even from a local path or any Youtube video URL
1 Like
Overview
Gemini Extension brings Google’s powerful, multimodal Gemini AI directly into MIT App Inventor, enabling you to build and customize any AI-driven API—text processing, OCR, image analysis, video intelligence, image editing, and more—without incurring extra third-party API fees
Why Gemini Extension?
By embedding Google’s state-of-the-art Gemini model (optimized in Ultra, Pro, and Nano sizes), this extension delivers enterprise-grade AI capabilities right inside your App Inventor projects—no external subscriptions required blog.google. You define your own JSON Schemas to guarantee structured, consistent outputs, eliminating parsing headaches and ensuring your data flows smoothly into your app
Key Features
Structured Outputs & Schemas
- JSON-Schema Enforcement: Supply any JSON Schema and Gemini Extension will strictly adhere to it, so your responses are always predictable and ready for use
Text Processing & NLP
- Advanced Language Tasks: Summarization, sentiment analysis, intent classification, and intelligent text generation—all powered by Gemini’s deep understanding of context and nuance blog.google.
OCR & Image Analysis
- Seamless Text Extraction: Leverage Google Cloud’s OCR API to convert images and documents into machine-readable text, complete with layout and language support Google Cloud.
- Free Credit on Signup: New users receive $300 of free Google Cloud credits, making it cost-effective to kickstart large-scale OCR projects Google Cloud.
Video Intelligence
- Smart Video Insights: Automatically detect objects, scenes, and explicit content in videos using Google Cloud Video Intelligence API—ideal for content moderation, metadata generation, and more Google Cloud.
Image Editing & Creative APIs
- AI-Powered Editing: Perform inpainting, outpainting, background removal, color adjustments, and more, all within your App Inventor blocks—no GPU management needed stablediffusionapi.com.
- Competitive Alternatives: While other services like Photoroom API and Phot.AI offer image editing, Gemini Extension integrates directly into your project, removing extra steps and costs Photoroomphot.ai.
Benefits
- Zero Extra API Costs: Build any custom AI pipeline without paying monthly fees to external providers—your only investment is the extension itself mit-cml.github.io.
- Rapid Development: Install in minutes, configure schemas visually in App Inventor, and start testing—all without backend setup or server maintenance.
- Scalable for Any Project: From hobby experiments to enterprise deployments with thousands of users, Gemini Extension handles it all under Google’s robust infrastructure.
- Full Customization: Mix and match features—combine OCR, NLP, image analysis, and video intelligence in a single workflow tailored to your app’s needs
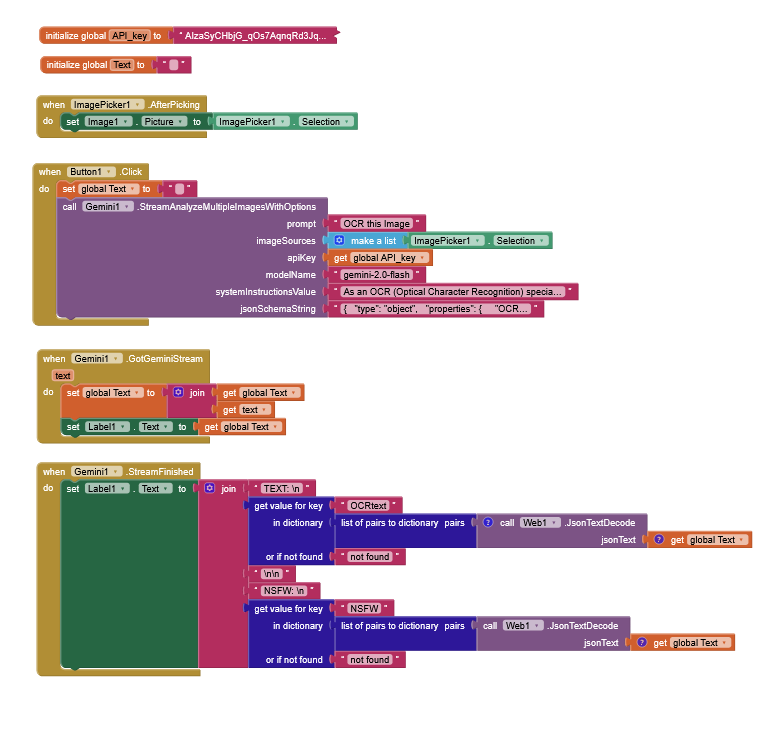
OCR Gemini customized API Example:
APK file
Try from here
Get Started Today
Transform the way you build AI features in MIT App Inventor with only 5.99$. Install Gemini Extension now, unlock Google’s Gemini AI, and craft the exact APIs your app demands—cost-efficiently, reliably, and at scale.
Hello,
I recently purchased your Gemini Extension for MIT App Inventor through PayPal, but I wasn’t redirected to the download link after payment was completed.
Could you please send the extension file (or the access link) directly to my email address at [mail id removed by mod, please do not post personal info, use PMs]
Let me know if you need any payment confirmation or transaction details.
Thank you for your support!
Best regards,
I am sorry for such a situation,
I have sent the Extension for you please check your email,
I hope this extension will move your app development to the next level.
Thanks,
New blocks added that will enhance the UX
files Upload Manager
Uploads a local file, waits for it to be processed (ACTIVE), " +
"and returns detailed metadata via the 'GotFileMetadata' event. " +
"Also reports progress via 'FileUploadProgress'.Reports the progress of a file upload (e.g., video, audio, pdf)."
Retrieves the direct download URI for the content of a file identified by its resource name (e.g., 'files/your_file_id'). " +
"Use this URI to download the file content directly (e.g., with Web component).

image understanding
Analyzes multiple images (from URLs/Paths) based on prompt, streaming results. Optionally provide system instructions and/or JSON schema. Results via GotGeminiStream/StreamFinished events.
Analyzes an image from URL based on prompt, streaming results. Optionally provide system instructions and/or a JSON schema for structured output. Results via GotGeminiStream/StreamFinished events.

video understanding
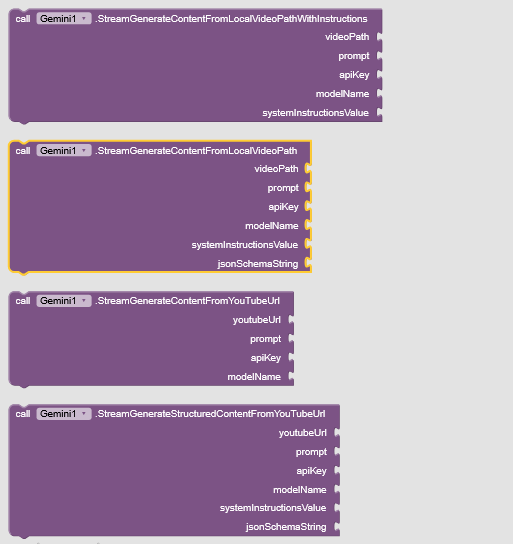
 HUGE Gemini Extension Update! Generate Mind-Blowing Audio!
HUGE Gemini Extension Update! Generate Mind-Blowing Audio! 
Get ready! You can now transform text into incredibly realistic speech with the NEW Text-to-Speech (TTS) service just added to your Gemini AI extension, powered by Google! ![]()
This isn't just any speech generator; it's INSANELY powerful! Create:
-
 Crystal-clear single voice narrations
Crystal-clear single voice narrations -
 Dynamic multi-speaker conversations (perfect for podcasts!)
Dynamic multi-speaker conversations (perfect for podcasts!) -
 And so much more!
And so much more!
Gemini Extension Update: Unlock the Web with URL Context!
We're excited to announce a powerful new feature for the Gemini extension: URL Context . This update allows your apps to give the Gemini model the ability to read and understand the content of web pages you provide directly in your prompt!
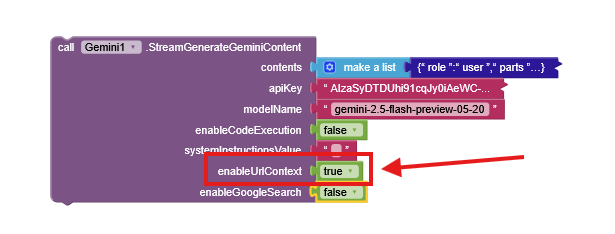
What is URL Context?
Imagine you want Gemini to summarize a news article, compare two product pages, or answer questions based on a specific blog post. Before, you would have to copy and paste all the text.
Now, you can simply include the web page links (URLs) in your prompt and enable the new enableUrlContext feature. Gemini will visit those URLs, read the content, and use that information to give you a much more relevant and contextual response.
This opens up amazing new possibilities, such as:
-
Article Summarization: "Summarize the key points of this article for me: [URL]"
-
Data Extraction: "Extract all the technical specifications from this product page: [URL]"
-
Content Comparison: "Compare the pros and cons of the cameras reviewed in [URL1] and [URL2]"
-
Question Answering: "Based on the information at [URL], what is the main ingredient in their recipe?"
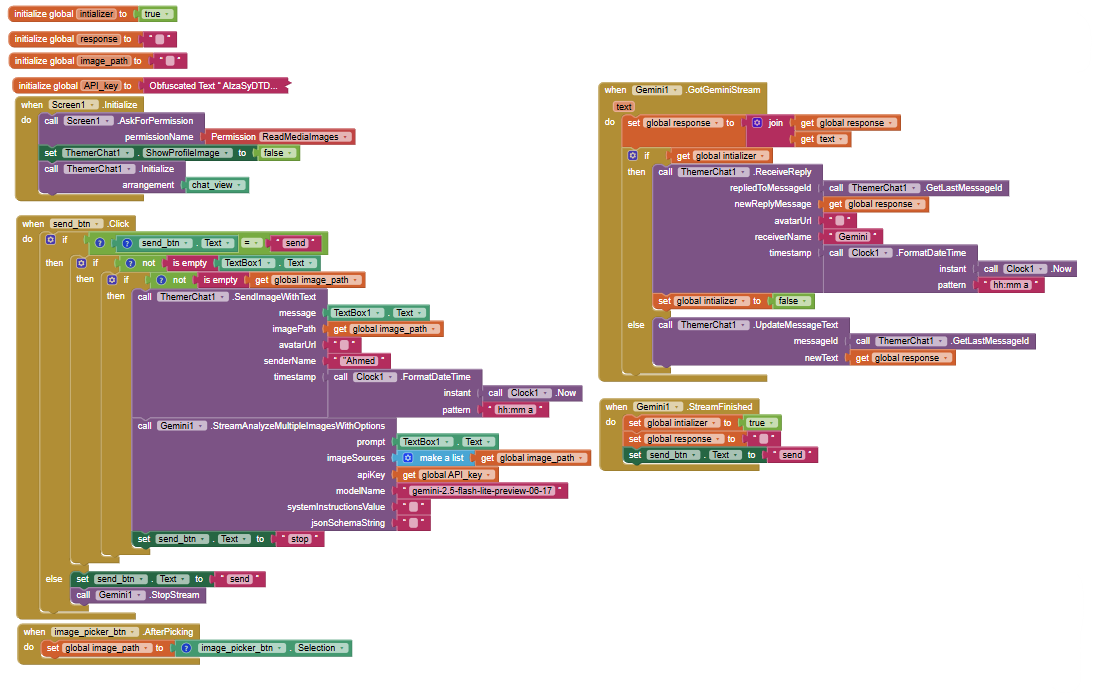
This is an example of how to use Gemini Vesion API with thermer chat extension
See the video :
")
The blocks :
New Update _gemini.aix
- Two old blocks of "single block response & streaming response" merged into this single block with new argument of
isStreaming: boolean

- Two blocks were added to make it easy and fast to ask the model one single question without continuous chat, unlike the previous function
GenerateGeminiContentblock that enables you to create continuous chat :


Can you please provide all features in one message
All Gemini extension features
-
Text Generation :
-
Simple Chat : Provides a basic Ask function for simple text-in, text-out conversations.
-
Advanced Generation : A powerful GenerateGeminiContent function that supports both single-turn and multi-turn conversations, system instructions, and optional tools.
-
Streaming : Offers streaming versions of all major generation functions (StreamGenerateGeminiContent, StreamGenerateGroundedContent, etc.) that provide the response in real-time chunks.
-
-
Image Understanding (Vision) :
-
Simple Image Queries : An AskWithImage block to ask questions about a single image.
-
Multi-Modal Analysis : The ability to send multiple images, videos, audio files, PDFs, and text in a single prompt for comprehensive analysis.
-
Multiple Input Sources : Accepts files from local paths, Base64 encoded strings, content URIs, and public URLs (for PDFs and images).
-
YouTube Video Analysis : Can analyze content directly from a public YouTube URL (including Shorts) when provided with a prompt.
-
-
Image Generation & Editing :
-
Text-to-Image : GenerateImage function to create an image from a text description.
-
Image Editing : EditImage and EditImageFromPath functions to modify an existing image based on a text prompt.
-
Multi-Image Editing : EditMultipleImagesSimple function to process a prompt against a list of images from various sources (URLs, paths, Base64).
-
-
Audio Understanding :
- Can process local audio files (e.g., MP3, WAV) as part of a prompt to be analyzed by the model.
-
Video Understanding :
- Can process local video files as part of a prompt, allowing the AI to analyze the video's content frame-by-frame.
-
Text-to-Speech (TTS) :
-
Single Speaker : GenerateSingleSpeakerSpeech function to convert text into speech using a specified prebuilt voice.
-
Multi-Speaker : GenerateMultiSpeakerSpeech function to create dialogue with multiple distinct voices from a structured script.
-
Advanced Features & Tools
-
Structured Output (JSON) :
-
Users can provide a JSON Schema to force the model to return its answer in a structured JSON format, making it easy to parse and use data in the app. This is supported by multiple functions.
-
Includes a CreateJsonSchema helper block to easily build the required schema.
-
-
Google Search Grounding :
- The StreamGenerateGroundedContent function can be enabled to have the model perform a Google search to ground its response in real-world information, providing source links for its claims.
-
Code Execution :
- The model can be given the ability to generate and execute code (like Python) to solve complex problems, with the results returned in the response.
-
File API Integration :
-
Efficient File Uploads : Includes robust functions to upload large files (like videos) directly to Google's servers. This is highly efficient as the file is processed on the server and referenced by a URI, avoiding the need to send the full file with every request.
-
File Management : Provides blocks to get detailed metadata (UploadFileAndGetMetadata) and the direct download link (GetFileContentUri) for uploaded files.
-
Reusability : Uploaded files can be reused in multiple API calls by referencing their URI.
-
Events and Callbacks
The extension is event-driven, providing specific events to handle different outcomes:
-
General Responses : RespondedToGemini (for single responses), GotGeminiStream (for each piece of a streaming response), and StreamFinished.
-
Image & Audio Generation : GotImageResponse (returns Base64 image data and a saved file path) and GotSpeechAudio (returns Base64 audio and a saved file path).
-
File Uploads : FileUploadProgress (provides real-time progress for large uploads) and FileUploadComplete / GotFileMetadata (fires when a file is uploaded and processed, returning its URI and details).
-
Error Handling : A robust ErrorOccurred event that provides detailed error messages for easier debugging.
-
API Key Validation : APIKeyValid, APIKeyInvalid, and APIKeyCheckError events to confirm if the provided API key works.
-
Grounding Sources : GotGroundingInfo event that returns a list of source URLs and titles when using Google Search.
Utility and Helper Functions
-
File Encoding : Multiple blocks to encode various file types (images, videos, PDFs) into Base64 format.
-
Path Conversion : A GetFilePathFromURI function to handle file paths provided by components like the Activity Starter or File Picker.
-
Permission Handling : Blocks to check for and request the necessary storage permissions on Android.
-
Image Display : A DisplayBase64Image helper to easily display a Base64 string in an Image component.
-
Model Management : A GetGeminiModelNames function to retrieve a list of all available models for the user's API key.
-
Favicon Fetcher : A simple utility to get the URL for a website's favicon.
Configuration
-
Designer Properties : The extension allows setting key parameters directly in the MIT App Inventor designer, including:
-
API Key and default Model Name.
-
Generation controls: Temperature, Top P, Top K, and Max Output Tokens.
-
Safety settings: Category and Threshold for content moderation.
-
Which gemini model needs to be used to access all features
There is no model that can access all features
-
For General Analysis (Text, Chat, Vision, Audio, Video):
- Use Gemini 1.5 Pro or Gemini 2.5 Pro . This covers most of the extension's features. For a faster alternative, use Gemini 1.5 Flash .
-
For Generating and Editing Images:
- Use an Imagen model (e.g., imagen-4).
-
For Generating Speech (Text-to-Speech):
- Use a Gemini TTS model (e.g., gemini-2.5-flash-preview-tts).

I'm excited to share a major update to the Gemini extension!
We've just added a powerful new feature: Image Editing . To celebrate, we are also introducing our most powerful and a-peeling model yet: the Nano Bananana AKA gemini-2.5-flash-image-preview model!
Now you can perform powerful image edits directly within your App Inventor projects. Take a look:
We are very excited to see what you can create with this new functionality.
Happy Inventing
Gemini 3 pro is here this is the game changer!
https://x.com/Google/status/1990924447402828120?t=1Avhi2kbi6XVDg7SQNkuQA&s=19

Major Update: Function Calling & Files API Integration!
Hello App Inventors!
We are thrilled to announce a game-changing update for the Gemini extension. This version transforms Gemini from a simple chatbot into a powerful AI Agent capable of controlling your app, while also giving you massive upgrades in file and image handling.
What's New?
Demo :
1. Function Calling: Turn Gemini into an Android Agent 
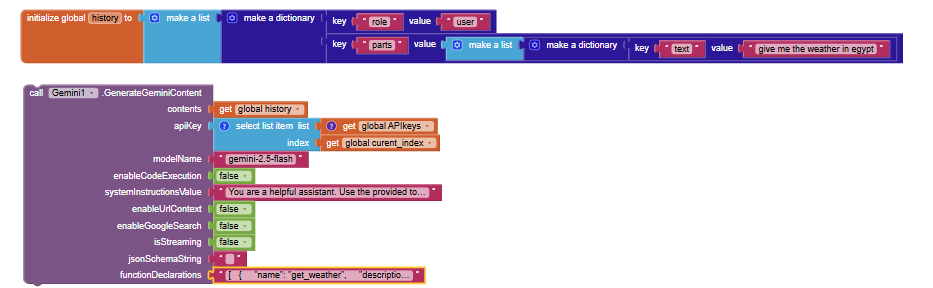
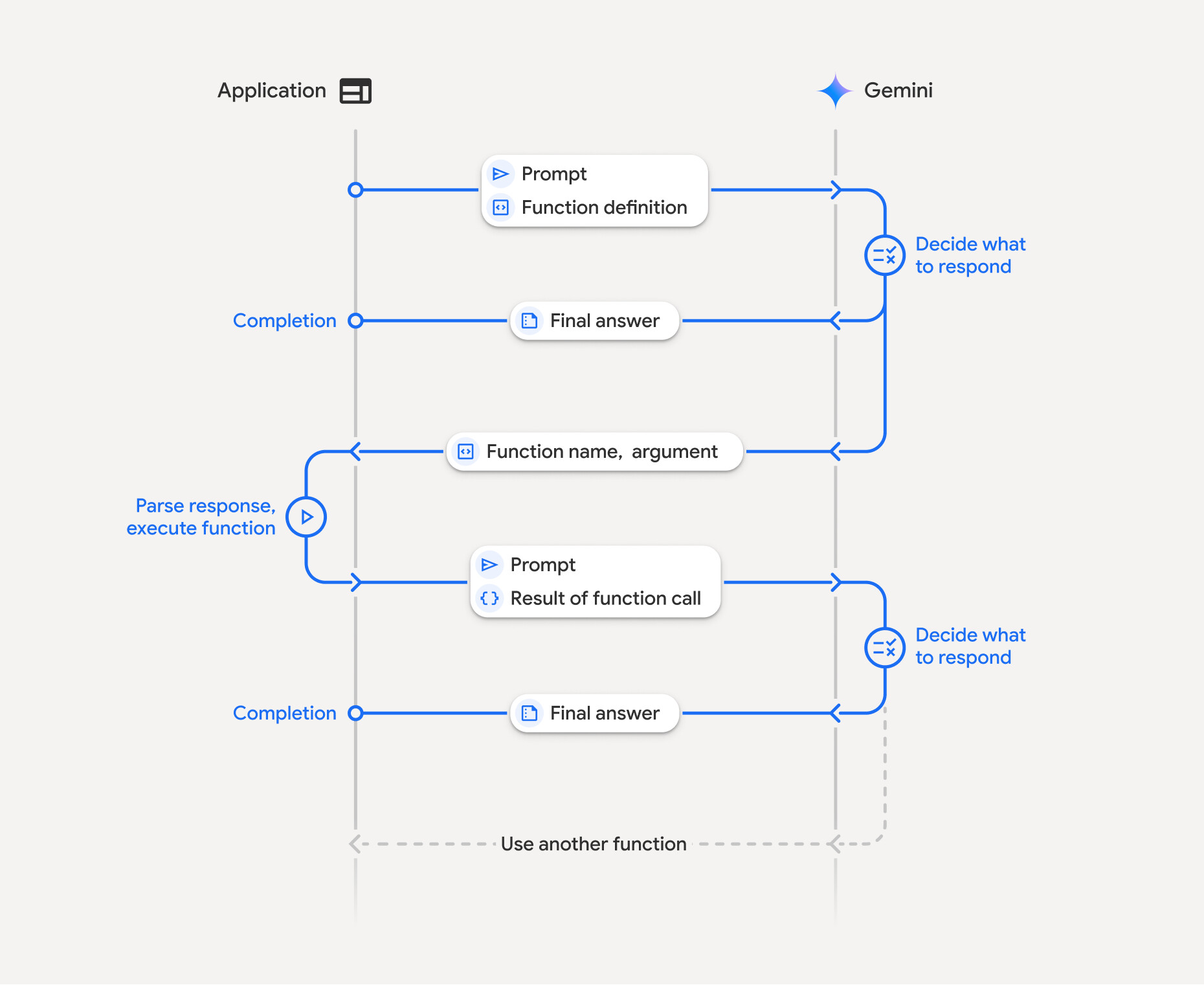
The biggest feature in this update is Function Calling. You can now teach Gemini how to use tools within your app!
Instead of just returning text, Gemini can intelligently decide to trigger events in your app based on the user's conversation.
How it Works (The Tool Loop):
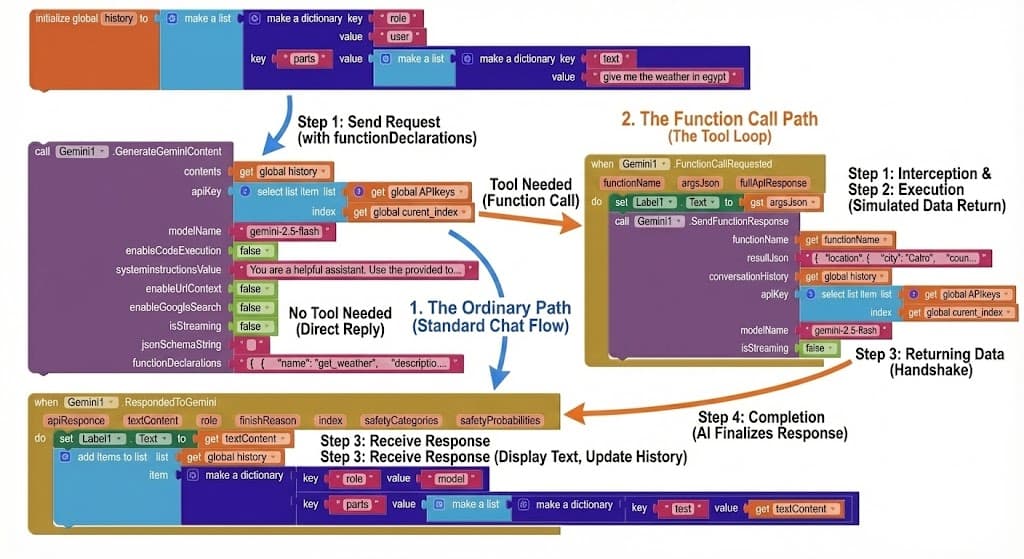
- Send Request: You provide a prompt ("Give me the weather in Egypt") and a list of tools your app has.
- Tool Needed: Gemini realizes it can't answer directly, so it asks you to run the
get_weathertool. - Execution: Your app runs the function (e.g., gets data from a weather API).
- Returning Data: You send the result (e.g., "30°C, Sunny") back to Gemini using SendFunctionResponse.
- Completion: Gemini uses that data to give a final natural language answer: "The weather in Egypt is 30°C and Sunny."
Example Declaration: Here is how you define a function for Gemini using the functionDeclarations parameter:
[
{
"name": "get_weather",
"description": "this function job to get weather status for specific location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string"
}
},
"required": [
"location"
],
"propertyOrdering": [
"location"
]
}
}
]
Key Blocks:
- DeclareFunctions: Define the available tools (like the JSON above).
- FunctionCallRequested (Event): Fires when Gemini wants to perform an action.
- SendFunctionResponse: Return the action's result back to the model.
2. Files API & Hybrid Image Engine 
We've completely overhauled how files and images are handled to eliminate size limits and boost performance.
 Hybrid Image Engine
Hybrid Image Engine
- Smart Switching: Small images (< 4MB) are processed instantly. Large images (> 4MB) automatically use the Files API.
- No More Limits: Send full-resolution 20MB+ raw photos without crashing your app!
 Full Files API Control
Full Files API Control
Manage your AI's knowledge base dynamically:
- UploadFile: Upload PDFs, Audio, Video, or Images to Gemini's cloud storage.
- ListUploadedFiles: View what's stored in your project.
- AskWithFile / AskWithUploadedFiles: "Read this PDF" or "Watch this video" and answer questions about it.
- DeleteFile: Manage your storage quota programmatically.
(Add a screenshot here of the new file management blocks)
Why Update?
- Build Agents: Create smart home assistants, personal schedulers, or data analysis bots that actually do things.
- Stable & Fast: The new image engine prevents "Payload Too Large" and Out-Of-Memory errors.
- Multimodal Power: Analyze huge documents and long videos with ease.
PAID_file
Price: 5.99$ not
7$for limited period
Purchase: PayPal Link or You can pay HERE using your credit card
In both cases after payment, you'll be redirected to the download URL. Contact me for any help or issues.
Happy Coding! ![]()
![]()
Hi everyone,
I'm working on v2 of the Gemini Extension, and I want to make sure it covers your specific use cases.
Instead of just asking for features, I want to know: What kind of AI app are you trying to build right now?
Are you building a chatbot assistant?
An educational app for homework help?
A tool to generate marketing text?
If you tell me what you are building, I can add the specific blocks or parameters to make that easier for you. Let me know in the comments!