Introduction
Hello everyone I am here today to introduce my new extension called ChatGPT,
Unlock the potential of artificial intelligence in your App Inventor projects with the ChatGPT Extension. This powerful tool empowers you to seamlessly integrate OpenAI's cutting-edge language models, enabling you to build sophisticated and engaging AI-powered features within your apps.
Why Choose the ChatGPT Extension?
Unleash True AI Power: Effortlessly integrate cutting-edge language, vision, and audio AI directly into your MIT App Inventor projects. Go beyond simple blocks!
Dynamic & Contextual Conversations: Create engaging chatbots that understand conversation history (when you provide it!), leading to more natural and meaningful user interactions.
Real-Time Web Search: Empower models like GPT-4o to access and incorporate the latest information from the web before responding, keeping your app's knowledge fresh. (Available via SendStreamedMessage)
Seamless Streaming (Chat, Vision & Audio!): Experience real-time interaction! Get API responses (text, image analysis, and now Text-to-Speech playback ) delivered in chunks for a super-responsive UI, eliminating long waits. (e.g., SendStreamedMessage, RequestStreamedAudioSpeech)
Versatile Audio Capabilities:
Speech-to-Text & Translation (Whisper): Accurately transcribe audio files or translate spoken language into English text. Perfect for voice input and accessibility. (e.g., RequestAudioTranscription, RequestAudioTranslation)
Text-to-Speech (TTS - File & Stream!): Generate natural-sounding speech in multiple voices. Choose to save audio files (RequestAudioSpeech) or play audio instantly as it streams (RequestStreamedAudioSpeech) for immediate feedback!
Unlock Visual Insights (GPT-4 Vision): Analyze images like never before! Provide images via URLs or local device files (even multiple images!) and get detailed descriptions, ask questions about visual content, and more. Available in standard and streaming modes. (e.g., RequestChatGPTVision, RequestChatGPTVisionStreamed)
Creative Image Generation (DALL-E): Bring imagination to reality! Generate unique images directly within your app from text descriptions using OpenAI's powerful DALL-E models. (e.g., RequestDALL_EImages)
Reliable Data Extraction (Structured Outputs): Need consistent data? Force API responses (from text or vision models) into your specific JSON format using custom schemas. Stop parsing messy text! (e.g., RequestCustomStructuredOutput, RequestCustomStructuredOutputVision)
Understand Text Deeply (Embeddings): Generate vector embeddings to unlock semantic search capabilities, text classification, clustering, recommendations, and deeper language understanding within your app. (e.g., GetEmbeddings)
Content Safety (Moderation): Automatically check text inputs or generated content for potential safety issues using OpenAI's Moderation endpoint. (e.g., RequestModeration)
Robust Error Handling: Built-in events (Error, SpeechSynthesisError, AudioStreamError, etc.) help you gracefully manage API issues and keep your users informed.
App Inventor Native: Designed from the ground up for seamless drag-and-drop integration into MIT App Inventor. No complex external libraries needed.
Incredible Value: Access this comprehensive suite of powerful AI features for just $5 (including a Tutorial AIA file)!
Blocks






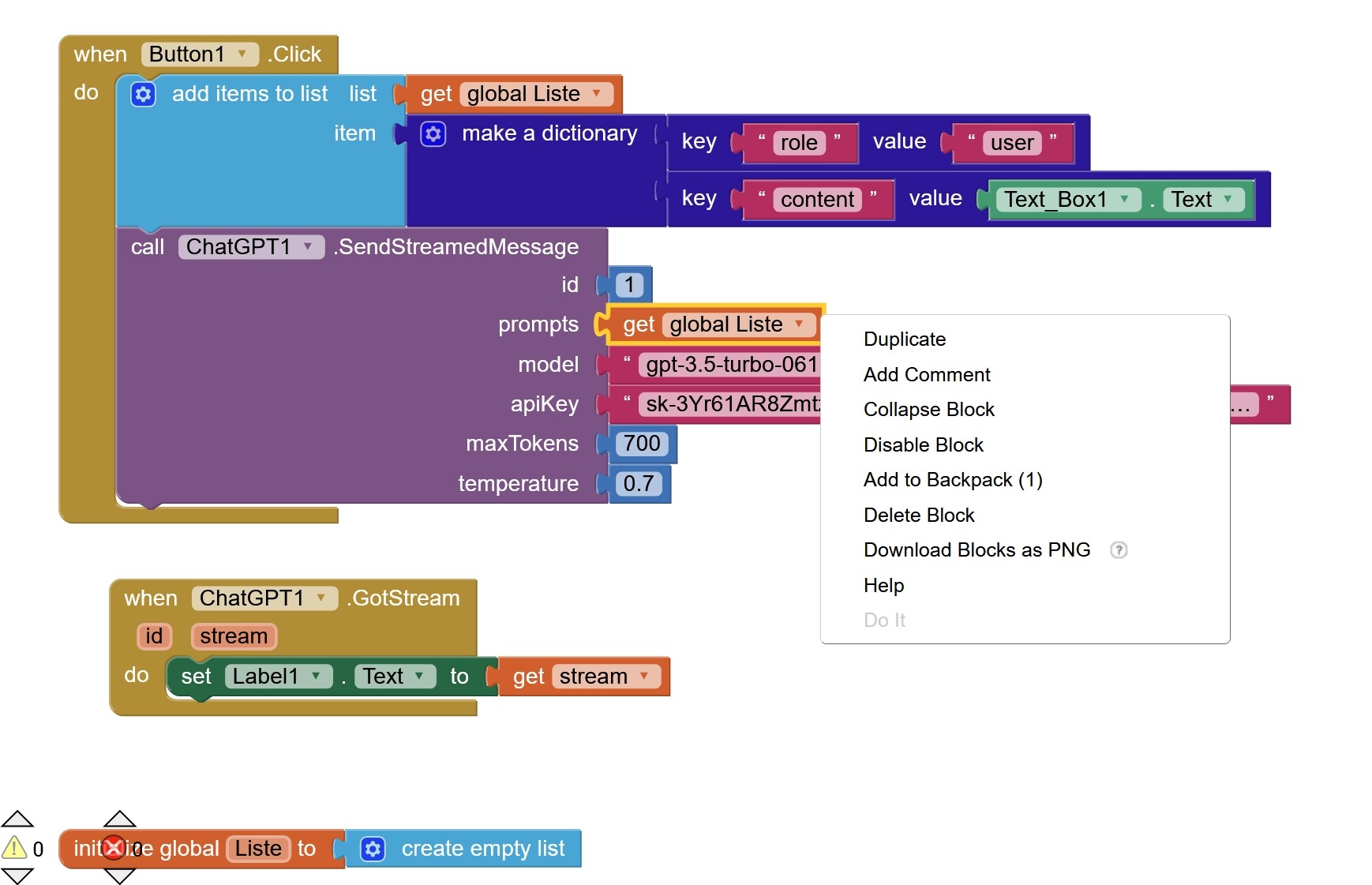
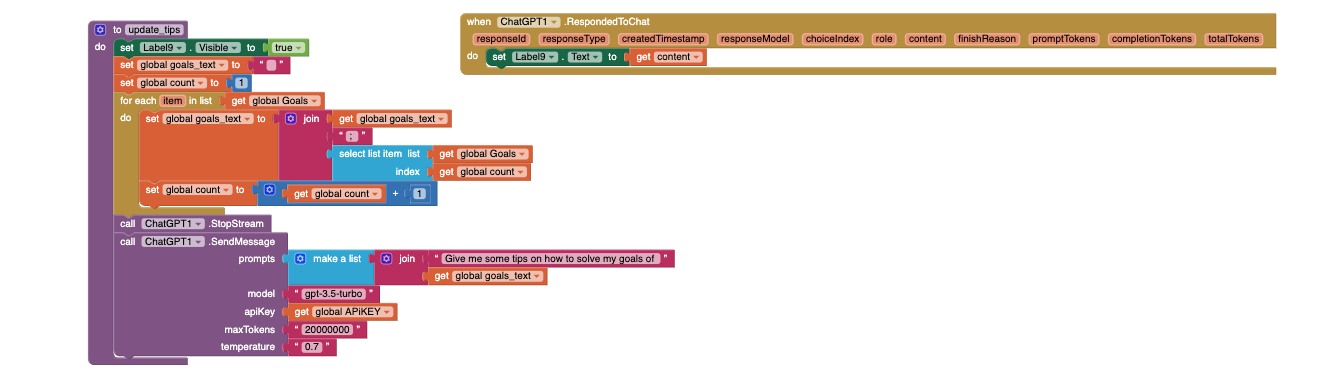
The SendMessage block is responsible for sending a conversation to the ChatGPT and processing the response. Here's a breakdown of the code:
- Block Description: This Block allows users to interact with the OpenAI ChatGPT and receive structured API-style responses.
- Function Parameters:
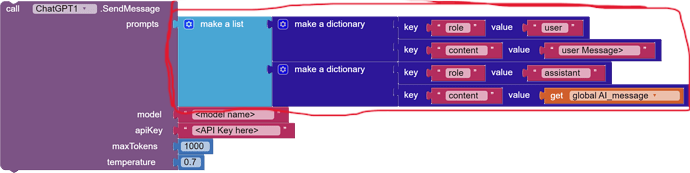
prompts: A list of conversation prompts provided by the user like in the block above .model: The name of the OpenAI model to be used.apiKey: The API key for authorization.maxTokens: The maximum number of tokens in the response.temperature: A value controlling the randomness of the response.
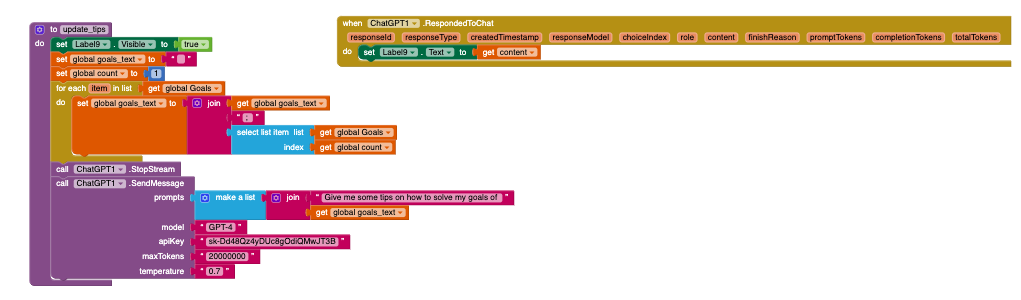
The RespondedToChat event is triggered when the OpenAI API successfully provides a response to a user's prompt sent through the SendMessage function. This event delivers the content of the response along with detailed metadata, including token usage information.
Parameters:
-
responseId (String): A unique identifier for the response generated by the OpenAI API.
-
responseType (String): The type of the response object. It usually indicates the nature of the response data structure (e.g., "chat.completion").
-
createdTimestamp (Number - long): The timestamp (in Unix epoch time, milliseconds) when the response was created by the OpenAI API.
-
responseModel (String): The specific OpenAI model that generated the response (e.g., "gpt-3.5-turbo", "gpt-4").
-
choiceIndex (Number - int): The index of the selected choice within the response. The OpenAI API may offer multiple response choices; this parameter indicates which one is being presented (typically 0 for the first and usually only choice).
-
role (String): The role associated with the message in the conversation. Common roles are "system" (for initial instructions), "user" (for the user's prompt), and "assistant" (for the AI's response).
-
content (String): The text content of the response generated by the OpenAI model.
-
finishReason (String): Indicates why the response generation process finished. It can be one of the following:
-
stop: The model reached a natural stopping point or a stop sequence was generated.
-
length: The maximum number of tokens (maxTokens parameter) was reached.
-
content_filter: Content was omitted due to a flag from OpenAI's content filters.
-
null: The API response is still in progress or incomplete (this value might be present if there are issues in receiving the complete response).
-
-
promptTokens (Number - int): The number of tokens used in the user's prompt. This value is now calculated before sending the request using a basic word-count approximation. It will not be the exact prompt token count but will be a close estimate.
-
completionTokens (Number - int): The number of tokens used in the generated response completion. This value is returned by the OpenAI API. If the key is not provided, it will default to 0.
-
totalTokens (Number - int): The total number of tokens used in the entire request and response (prompt tokens + completion tokens). This value is returned by the OpenAI API. If the key is not provided, it will default to 0.
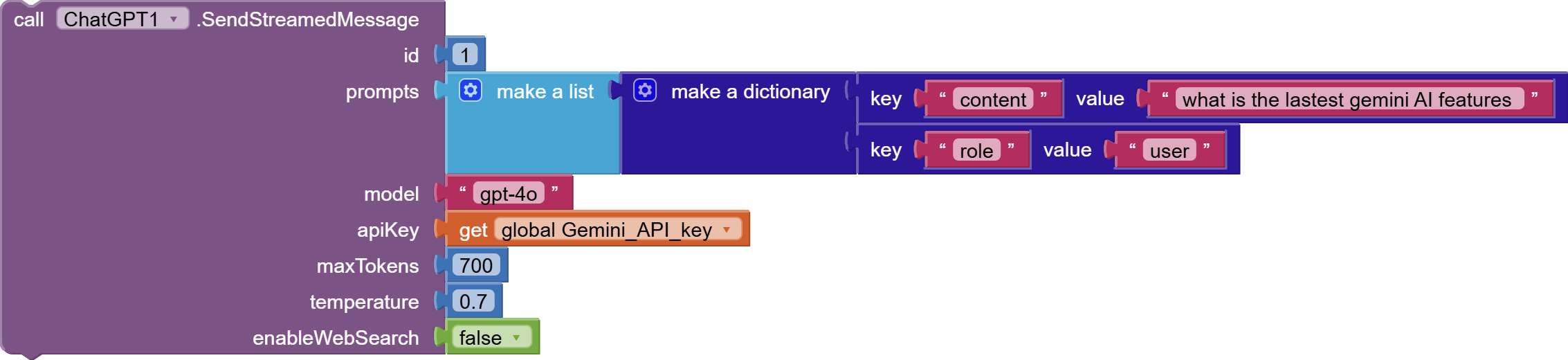
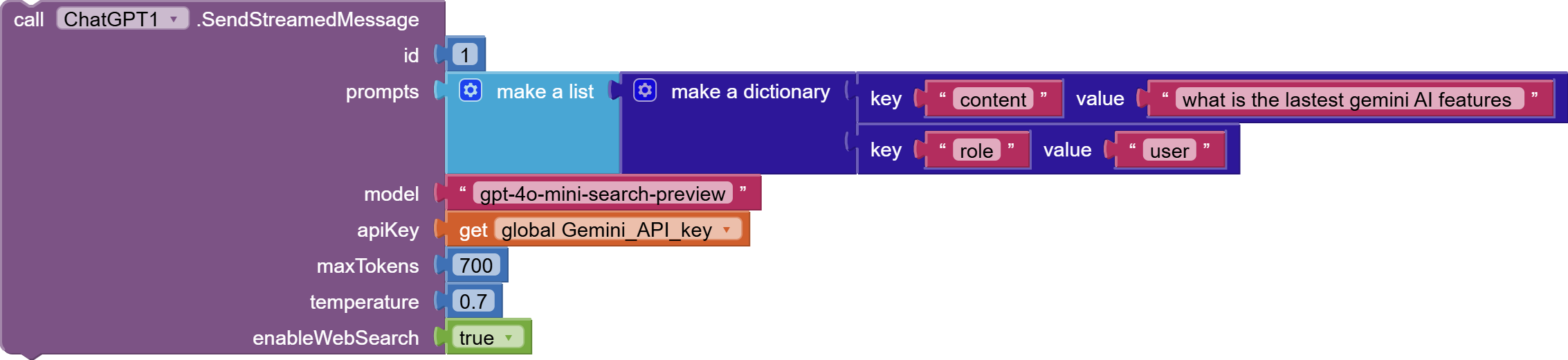
The SendStreamedMessage function is designed to send a series of prompts to the OpenAI Chat Completions API and receive responses in a streaming manner. This version of the function includes an option to enable or disable web search capabilities and incorporates enhanced error handling to manage potential issues during the API request and response processing.
Function Parameters:
-
id(int): A unique identifier for the message stream, used to track and manage the streaming process. -
prompts(YailList): A list of dictionaries, each containing a 'role' and 'content' key, representing the sequence of messages in the conversation. -
model(String): The code representing the desired OpenAI model to be used for generating responses, but in case of "enableWebSearch"= true you can only use one of these models *gpt-4o-search-previeworgpt-4o-mini-search-preview. -
apiKey(String): The API key for authenticating requests to the OpenAI API. -
maxTokens(int): The maximum number of tokens to generate in the response. -
temperature(double): Controls the creativity of the response; higher values result in more creative outputs. -
enableWebSearch(boolean): Determines whether to enable web search capabilities during the response generation.


The StoppedStream Block is an essential component in managing streaming operations and is triggered when the streaming process is manually stopped by calling the StopStream Block

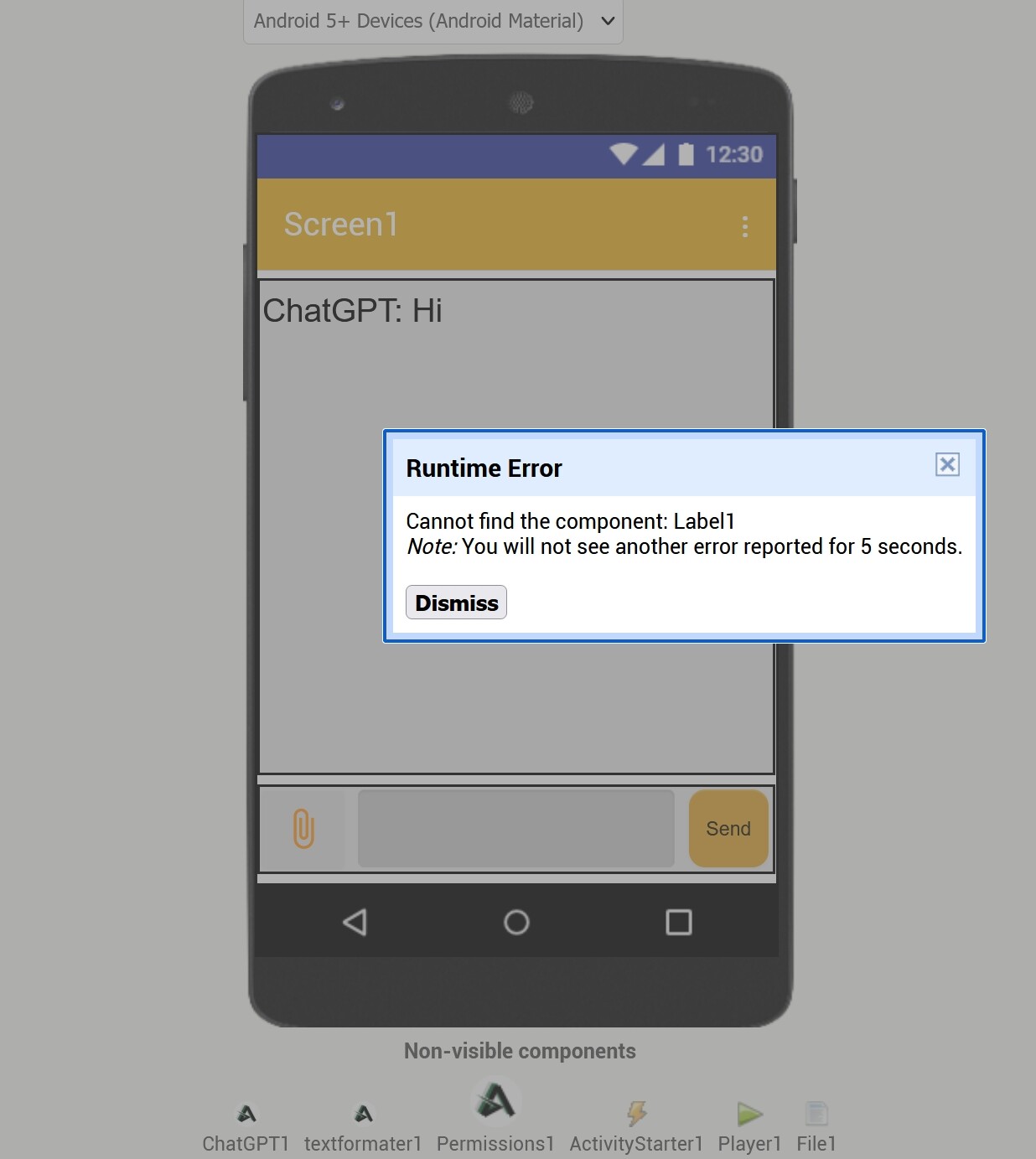
The GotStream event is fired repeatedly during an ongoing streaming conversation initiated by the SendStreamedMessage function. Each time the OpenAI API sends a chunk of the response, this event is triggered, delivering the partial response content along with updated token usage information.
Parameters:
-
id (Number - int): A user-defined identifier that was originally passed to the SendStreamedMessage function. This ID helps to distinguish between different streaming conversations if multiple are happening concurrently.
-
stream (String): The partial text content of the response received in the current chunk from the OpenAI API.
-
completionTokens (Number - int): An approximate number of tokens in the current stream chunk. This value is calculated using a basic word-count method similar to the prompt token approximation.
-
totalTokens (Number - int): The running total of estimated tokens (prompt + completion) up to this point in the stream. The prompt tokens are approximated before sending the request, and the completion tokens are accumulated as each chunk is received.

The FinishedStream event is used to notify when all chunks of a stream have been returned through the GotStream event, indicating the completion of the streaming conversation.
RequestModeration
Description: This function asynchronously requests content moderation using the OpenAI Moderation API. It takes an API key and input text as parameters, sends a POST request to the API endpoint, and processes the response.
Parameters:
apiKey(String): The API key for accessing the OpenAI Moderation API.input(String): The input text or content to be moderated.
ModerationResult
Description: This event is triggered when the moderation result is received from the OpenAI Moderation API. It provides information about whether the content is flagged, categories, and category scores as parameters.
Parameters:
flagged(boolean): Indicates whether the content is flagged.categories(String): JSON representation of the detected categories.categoryScores(String): JSON representation of the scores for each category.
Usage: Handle this event to perform actions based on the moderation result, such as updating the user interface or taking appropriate actions based on the moderation outcome.

RequestAudioSpeech Function
Description: This function asynchronously requests audio speech synthesis from OpenAI's Audio Speech API, utilizing specified parameters such as API key, model, input text, voice, optional instructions, folder path, and file name. The synthesized speech is saved as an MP3 file in the designated location.
Parameters:
-
apiKey (String): Your API key for accessing OpenAI's Audio Speech API.
-
model (String): The model used for speech synthesis. Options include:
tts-1: Optimized for real-time text-to-speech applications.tts-1-hd: Optimized for higher-quality speech synthesisgpt-4o-mini-tts: Built on GPT-4o mini, offering fast and powerful text-to-speech capabilities.
-
textInput (String): The text to be synthesized into speech.
-
voice (String): The voice selection for audio generation. Supported voices are:
-
alloy -
ash -
ballad -
coral -
echo -
fable -
onyx -
nova -
sage -
shimmer -
instructions (String, optional): You can provide specific instructions to potentially influence the tone, style, or delivery of the speech (e.g., "Speak in a cheerful and positive tone."). Leave blank if not needed.
-
folderPath (String): The directory path where the resulting MP3 file will be saved.
-
fileName (String): The name assigned to the saved MP3 file.

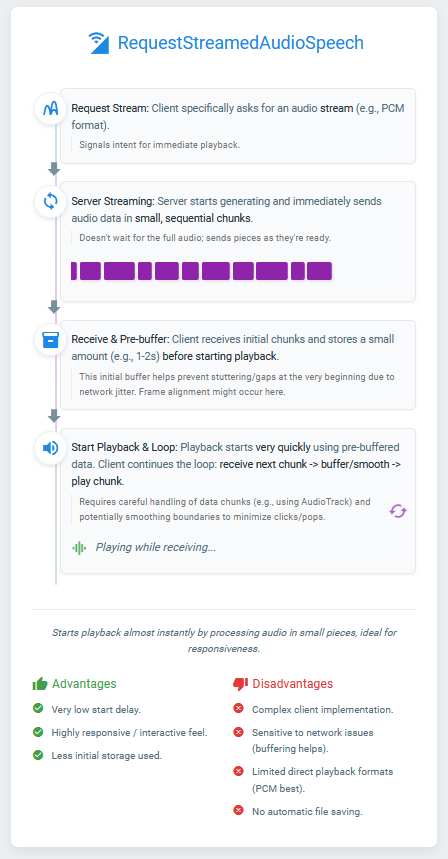
StreamAudioSpeech
Description
Streams audio speech synthesis from OpenAI in real-time and plays it directly through the device speaker. This function is optimized for low latency playback, starting audio almost immediately as it arrives.
It specifically uses the gpt-4o-mini-tts model and requests audio in PCM format, which is required for the direct playback mechanism. The function incorporates pre-buffering, frame alignment, boundary smoothing (cross-fading), and a final fade-out to minimize glitches and provide a smoother listening experience.
Use the separate StopStream block to halt playback manually.
Parameters
-
apiKey (Type: Text)
- Required. Your unique API key for accessing OpenAI services.
-
textInput (Type: Text)
- Required. The text content you want the AI to speak.
-
voice (Type: Text)
- Required. The desired voice for the speech synthesis. Valid options include: alloy, echo, fable, onyx, nova, shimmer. (Note: The underlying model might support more voices than the older TTS-1).
-
instructions (Type: Text)
- Optional. You can provide specific instructions to potentially influence the tone, style, or delivery of the speech (e.g., "Speak in a cheerful and positive tone."). Leave blank if not needed.
-
Note: The model and responseFormat are fixed internally by this function:
-
Model: gpt-4o-mini-tts
-
Response Format: pcm (Raw Pulse Code Modulation audio data)
-
Events Triggered
This function can trigger the following events:
-
StartedAudioStream()
- Fired shortly after the request is made, once enough initial audio data (pre-buffer) has been received and playback is about to begin. Use this to indicate to the user that the audio is starting.
-
FinishedAudioStream()
- Fired only when the entire audio stream has been successfully received from OpenAI and played through to the end naturally (without being manually stopped).
-
AudioStreamError(errorMessage Text)
-
Fired if any error occurs during the process:
-
Invalid API key or network issues.
-
Errors reported by the OpenAI API.
-
Problems initializing the device's audio player (AudioTrack).
-
Errors during data writing or processing.
-
-
The errorMessage parameter provides details about the failure.
-
-
StoppedAudioStream()
- Important: This event is NOT directly fired by StreamAudioSpeech itself upon completion. It is fired when you explicitly call the StopStream block to manually interrupt the ongoing audio playback. If the stream is stopped manually, FinishedAudioStream will not be fired.
How It Works (Simplified)
-
Request: Sends your text and parameters to OpenAI, specifically requesting a pcm audio stream from the gpt-4o-mini-tts model.
-
Pre-buffer: Receives the first small portion of audio data from OpenAI and holds it temporarily.
-
Initialize Player: Sets up the device's low-level audio player (AudioTrack) configured for the specific PCM format (e.g., 44.1kHz, 16-bit Mono).
-
Write & Play: Writes the pre-buffered data to the player and immediately starts playback.
-
Stream Loop: Continuously receives subsequent small chunks of audio data from OpenAI.
-
Smooth & Play: For each incoming chunk:
-
It checks if there's a large, potentially audible jump (discontinuity) between the end of the last played chunk and the start of the new one.
-
If a jump is detected, it applies a very short fade-in to the beginning of the new chunk to smooth the transition, reducing clicks/pops.
-
It ensures only complete audio frames (pairs of bytes for 16-bit PCM) are sent to the player.
-
The processed chunk is sent to the player to be heard.
-
Final Fade-Out: When the stream from OpenAI ends naturally, a short fade-out is applied to the very last segment of audio for a less abrupt ending.
-
Finish/Error/Stop: Triggers the appropriate event (FinishedAudioStream, AudioStreamError, or relies on StopStream triggering StoppedAudioStream).
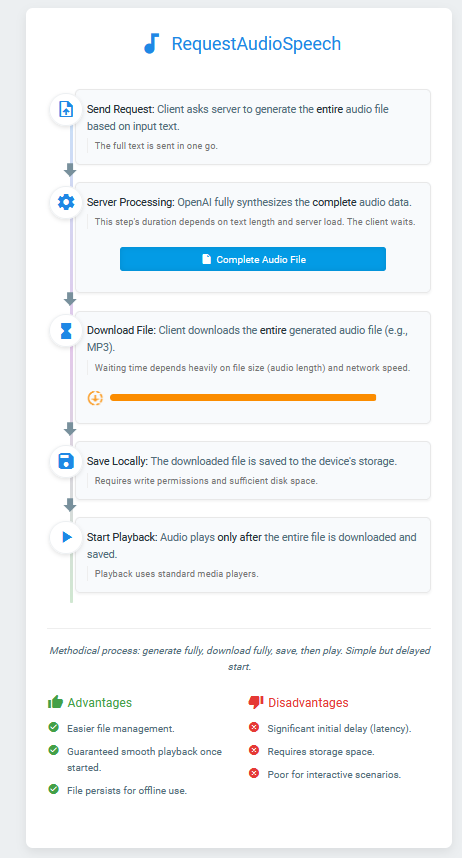
Audio Generation: File Download vs. Real-time Stream
Exambles
- Alloy :
- Echo :
- Fable :
- Onyx :
You can try other voices
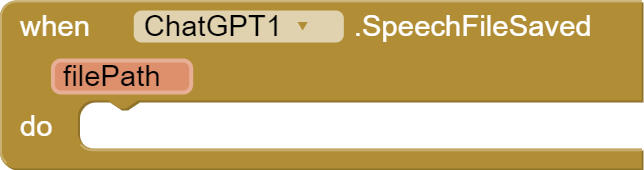
SpeechFileSaved Event
Description: This event is fired when the MP3 file has been successfully saved. It provides the file path as a parameter.
Parameters:
filePath(String): The path where the MP3 file has been saved.
Usage: Handle this event to perform actions after the MP3 file has been successfully saved.
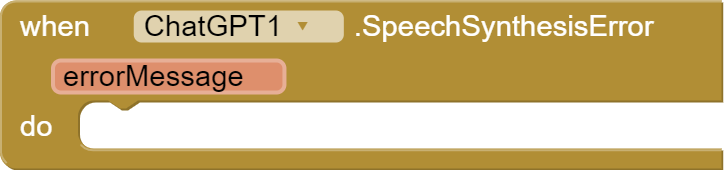
SpeechSynthesisError Event
Description: This event is fired when an error occurs during the audio speech synthesis process. It provides an error message as a parameter.
Parameters:
errorMessage(String): The error message describing the issue encountered.
Usage: Handle this event to capture and handle errors during the speech synthesis process.

RequestAudioTranscription
Block is responsible for making a request to OpenAI's Audio Transcriptions API to transcribe audio from a provided audio file. (Transcribes audio into the input language.)
The Blcok takes four parameters:
-
apiKey(API key for authentication), -
audioFilePath(path to the audio file to be transcribed), -
model(model configuration), you can set it aswhisper-1 -
responseFormat( The format of the transcript output, in one of these options:json,text,srt,verbose_json, orvtt).

The AudioTranscriptionReceived block, its purpose is to notify the application when audio transcription data is received

The RequestAudioTranslation block is designed to request audio translation from OpenAI's Audio Translations API and return the "text" value from the response.
Parameters:
The function takes three parameters:
-
apiKey(API key for authorization), -
audioFilePath(path to the audio file to be translated), -
model(the model used for translation).
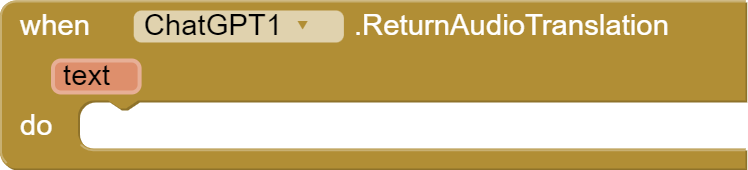
This ReturnAudioTranslation event is triggered when the audio translation response is received.
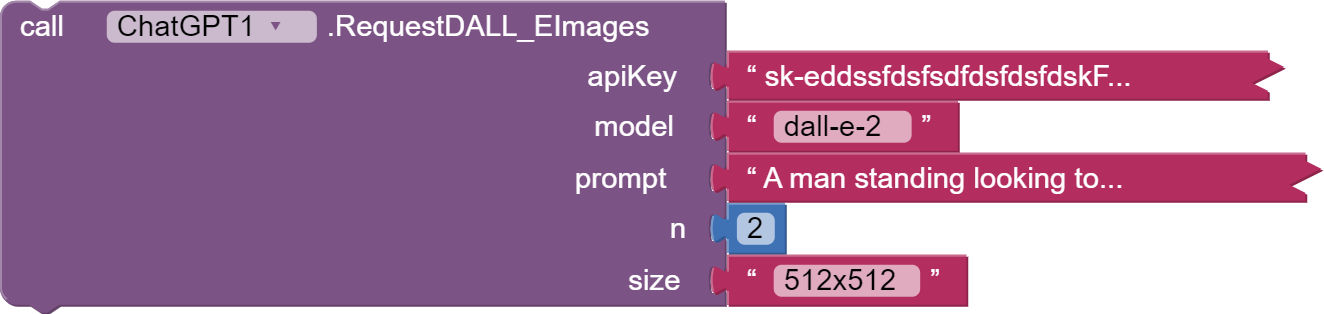
RequestDALL_EImages
Description
This function initiates a request to the OpenAI DALL-E Images API to generate images based on a given prompt.
Parameters
-
apiKey(String): The API key for authentication. -
model(String): (Optional) The model to use for image generation, defaults to "dall-e-2". -
prompt(String): A text description of the desired image(s) (Required). The maximum length is 1000 characters for dall-e-2 and 4000 characters for dall-e-3. -
n(int): (Optional) The number of images to generate, defaults to 1. Must be between 1 and 10. For dall-e-3, only n=1 is supported. -
size(String): (Optional) The size of the generated images, defaults to "1024x1024". Must be one of "256x256", "512x512", or "1024x1024" for dall-e-2. Must be one of "1024x1024", "1792x1024", or "1024x1792" for dall-e-3 models.
Events

DALL_EImagesGenerated(List imageUrls): Fired when the DALL-E Images API successfully generates images. Returns a list of image URLs.
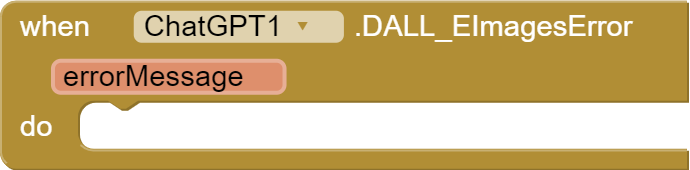
DALL_EImagesError(String errorMessage): Fired when an error occurs during the DALL-E Images API request. Returns an error message.
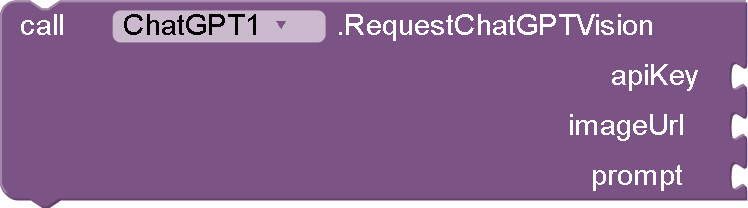
Function: RequestChatGPTVision(String apiKey, String imageUrl, String prompt)
Purpose: This function sends a request to OpenAI's ChatGPT vision API to analyze an image and provide insights based on the given prompt.
Parameters:
-
apiKey: Your OpenAI API key.
-
imageUrl: The URL of the image to analyze.
-
prompt: A text prompt to guide the analysis (e.g., "What's in this image?").

Function: RequestChatGPTVisionMultipleImages(String apiKey, YailList imageUrls, String prompt)
Purpose: This function sends a request to OpenAI's ChatGPT vision API to analyze multiple images and provide insights based on the given prompt.
Parameters:
-
apiKey: Your OpenAI API key.
-
imageUrls: A YailList containing the URLs of the images to analyze.
-
prompt: A text prompt to guide the analysis (e.g., "Compare these images").

RequestChatGPTVisionFromFile
Purpose: Analyzes a single local image file and provides insights based on a text prompt.
Parameters:
-
apiKey: Your OpenAI API key.
-
imagePath: The file path of the image to analyze.
-
prompt: A text prompt to guide the analysis (e.g., "What's in this image?").
-
detail: The desired level of detail for the analysis (
low,high, orauto). -
maxTokens: The maximum number of tokens allowed in the API response.

RequestChatGPTVisionMultipleImagesFromFile
Purpose: Analyzes multiple local image files and provides insights based on a text prompt.
Parameters:
-
apiKey: Your OpenAI API key.
-
imagePaths: A YailList containing the file paths of the images to analyze.
-
prompt: A text prompt to guide the analysis (e.g., "Compare these images").
-
detail: The desired level of detail for the analysis (e.g., "high").
-
maxTokens: The maximum number of tokens allowed in the API response.
Events:

-
ChatGPTVisionResponseReceived : This event is fired when the API response is successfully received and parsed. It provides the following parameters:
-
id: The unique ID of the response.
-
object: The type of object returned ("chat.completion").
-
model: The model used to generate the response.
-
role: The role of the response ("assistant").
-
content: The main content of the response, containing the analysis of the image.
-
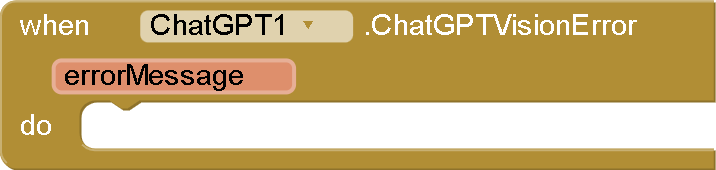
-
ChatGPTVisionError(String errorMessage) : This event is fired if an error occurs during the API request. It provides the error message.
-
The response content will vary depending on the image and the prompt provided.
ChatGPT Extension- Embeddings Functionality
1. GetEmbeddings(String apiKey, String text, String model)
-
Description: This function sends a request to OpenAI's Embeddings API to get the numerical representation (embedding) of a given text.
-
Parameters:
-
apiKey: Your OpenAI API key (required for authentication).
-
text: The text string you want to embed.
-
model: The specific embedding model you want to use (e.g., "text-embedding-ada-002, text-embedding-3-small ,text-embedding-3-lar").
-
-
Functionality:
-
It constructs an API request with your text and the chosen model.
-
It sends this request to OpenAI's server.
-
It then calls the processEmbeddingsAPIResponse function to handle the server's response.
-
-
Events Triggered:
-
EmbeddingsReceived: Fired upon a successful response, containing the embeddings.
-
EmbeddingsError: Fired if an error occurs during the request.
-
2. EmbeddingsReceived(String embeddings)
-
Description: This event is fired when the GetEmbeddings function successfully receives a response from the OpenAI API.
-
Parameter:
- embeddings: The text's embedding, returned as a string representation of a list of numbers.
3. EmbeddingsError(String errorMessage)
-
Description: This event is fired when an error occurs at any point during the embedding request process.
-
Parameter:
- errorMessage: A descriptive error message to help you understand the issue.
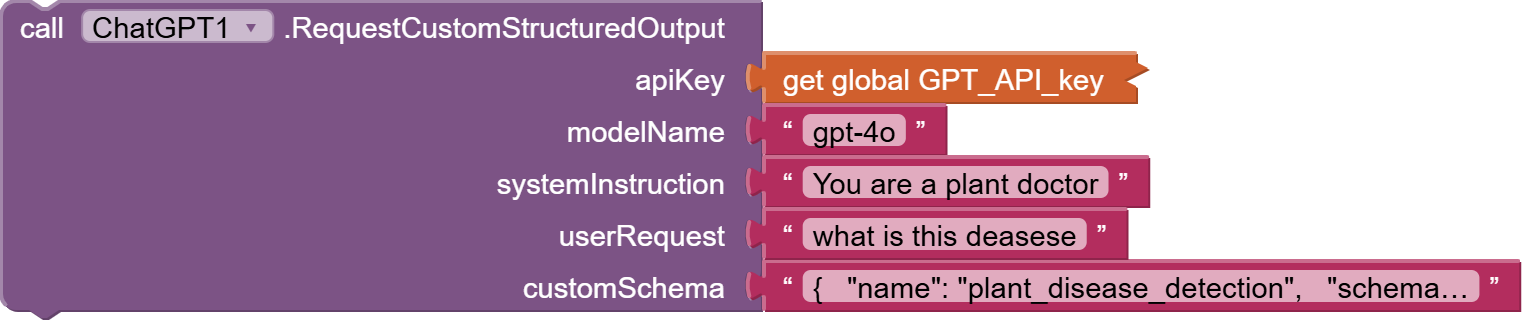
The RequestCustomStructuredOutput function allows you to send a prompt to an OpenAI model and receive a response structured according to a custom JSON schema. This ensures that the model's output adheres to a specific format, facilitating easier parsing and integration into applications.
apiKey(String): Your OpenAI API key for authentication.modelName(String): The identifier of the OpenAI model to use (e.g., "gpt-4o-2024-08-06").OpenAIsystemInstruction(String): Instructions provided to the model to set context or behavior.userRequest(String): The user's input or query that the model will respond to.customSchema(String): A JSON-formatted string defining the desired structure of the model's output. you can get your customized Schema from here
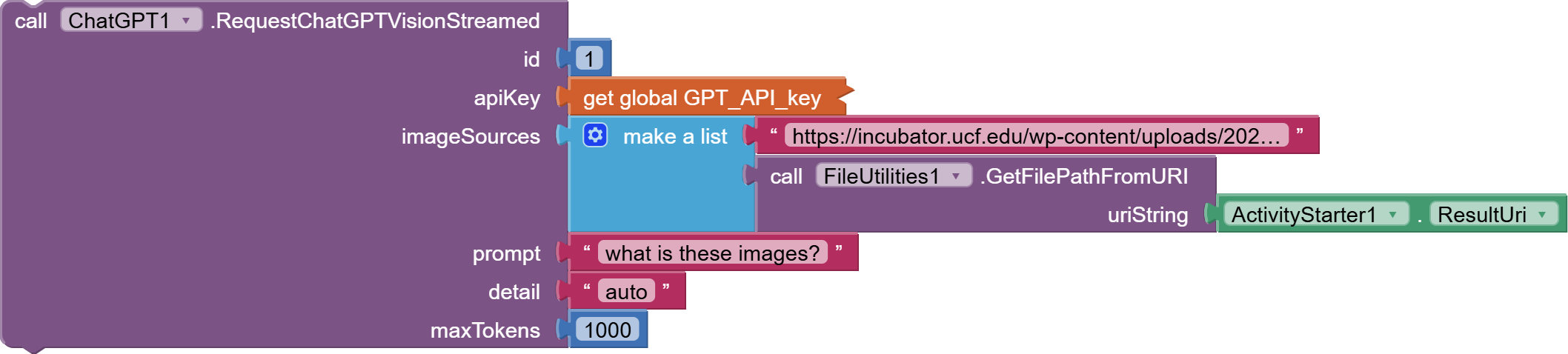
The RequestCustomStructuredOutput function
Description:
Sends a prompt to an OpenAI model using both text and image inputs. This function accepts a custom JSON schema to structure the output and supports image sources provided as URLs or local file paths (which are encoded in Base64).
Parameters:
- apiKey (String): Your OpenAI API key.
- modelName (String): The identifier of the model (e.g., "gpt-4o-2024-08-06").
- systemInstruction (String): Instructions to set the context for the model.
- userRequest (String): The main text prompt from the user.
- customSchema (String): A JSON-formatted string defining the expected structure of the model's response.
- imageSources (YailList): A list of image source strings. Each item can be either a URL (starting with "http://" or "https://") or a local file path.
Events:
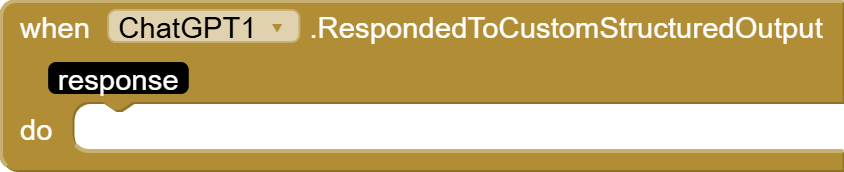
RespondedToCustomStructuredOutput(String response): Triggered when the model returns a response adhering to the custom schema. Theresponseparameter contains the structured data as a JSON string.
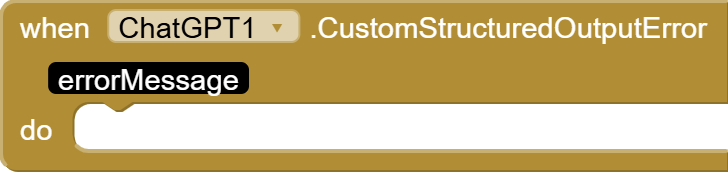
CustomStructuredOutputError(String errorMessage): Triggered when an error occurs during the request. TheerrorMessageparameter provides details about the issue.
Considerations:
-
Schema Validation: Ensure that the
customSchemaparameter is a valid JSON schema. An invalid schema may result in errors or unexpected behavior. -
Model Compatibility: Verify that the specified
modelNamesupports structured outputs. For instance, models likegpt-4o-2024-08-06are designed to adhere strictly to provided schemas.
preview :
I also use this Extension in this project :
Aix file :
you can purchase the AIX and the AIA file from here via PayPal the two files cost 5$ after you pay you will be automatically redirected to the download URL of the extension