Problem Description:
How to allow an imported p5.js file (Tensorflow file from Teachable Machine) running as a 'html", to use the microphone and collect the speech samples ?
Is there a better way to use ML models from Teachable Machine ?
Development History:
Teachable Machine ML model created to recognize voices of 3 people. Final accuracy is between 70-90% (when run on the Teachable Machine platform with my Window laptop and a built in microphone).
Now I want to use the model in my MIT AppInventor app by extracting it from the Teachable Machine in a Tensorflow.js file version so it can be run in a browser as a html file.
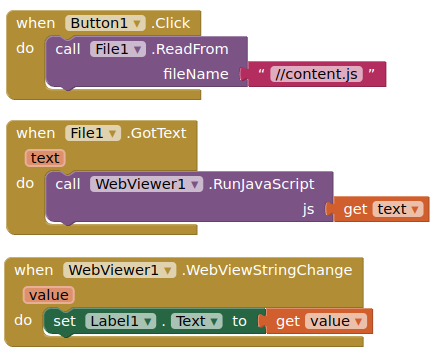
My plan was (is) to use the WebViewer1 component as a framework and communicate with the imported ML model code (html file) by using::
window.AppInventori.getWebString()
window.AppInventori.setWebString()
I copy-pasted the ML model code snippet provided by the Teachable Machine (Tensorflow.js / p5.js) into a text editor and saved it with a "html" extension.
The first goal was to make the simplest, basic AppInventor app that can just start running the ML model. Here is the status of the testing so far:
a) My laptop (Windows 10, Google Chrome Version 109.0.5414.75 (Official Build), 64-bit),
Running the downloaded ML Model code ("person_voice_model_30epoch.html") in the browser by double clicking on it
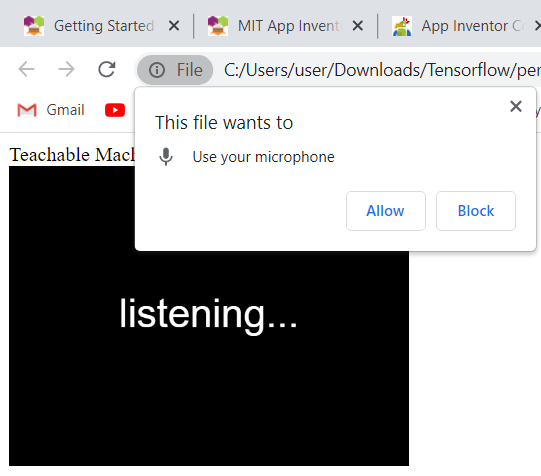
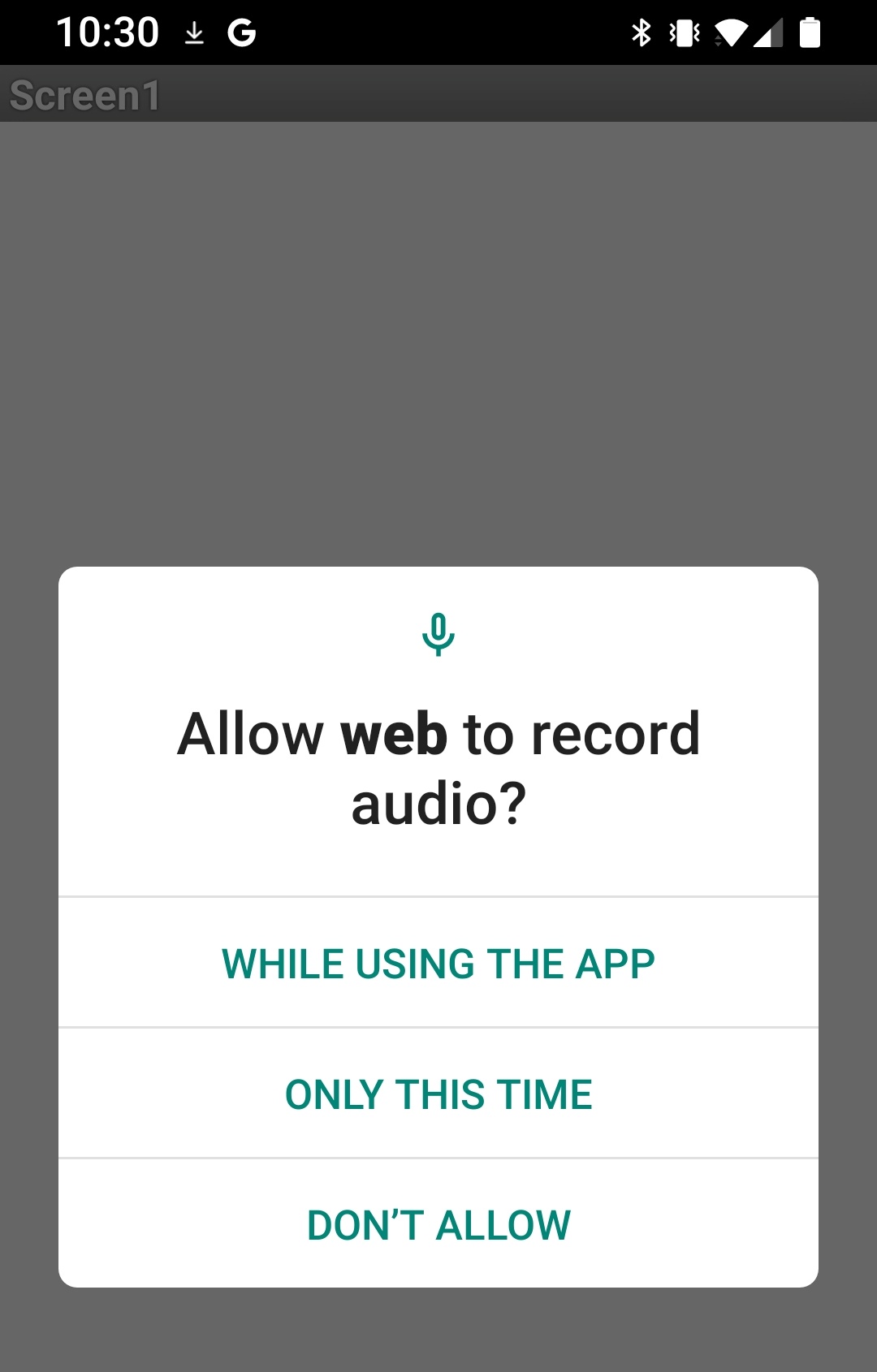
The "model" starts, sets the "screen", and "prints" the text (label) "listening" while "asking" and waiting for permission to use the microphone (please see screenshot ILL 1).
After the permission is granted, the model works well
b) In my AppInventor app, on my smartphone (OnePlus 6T, Android version 11) I am experiencing challenges.
Uploaded the "ML model file" (html) to my app as a Media file (under the WebViewer1 component)
After "Screen1" initializes, the app activates the js script (the uploaded html model) but sits in the 1st step, wiht the text (label) "listening" on the screen (please seee screnshot Ill 2)
Most likely, the ML code is waiting on permission to use the microphone but that request popup window never shows up (unlike in the scenario "a" above")
Please see the ILL 3
What was tried:
Tried with "SoundRecorder" and "Speech Recognizer" Media components (activate them in a hope that it will "somehow enable" the microphone but obviously, no results.
Looked through Q&A in MIT AppInventor Forums and YouTube and saw some examples where a "Sound Sensor" was called and used (activated etc) in a context of handling sound recording / microphone, but I can not locate Sound Sensor in my App Inventor ..?
Questions:
Any suggestion on how to allow that imported ML code (run as html in browser) to access the microphone in order to collect the voice samples ?
Is there a better way to embed / use Teachable Machine ML models in MIT App Inventor ?
[I can comprehend java and html but am not a skillful java developer]
Hi Chris
Adding Speech Recognizer doesn't change the behavior of the java script (html file)
Tried also with "Call WebViewer.RunJavaScript" and directing it to the uploaded model code snipped saved as a html or "js" file type, but with that approach, the app didn't even initialize the screen (as it did before)
Now going to upload the CustomWebView extension and see if that would offer a solution
Milan
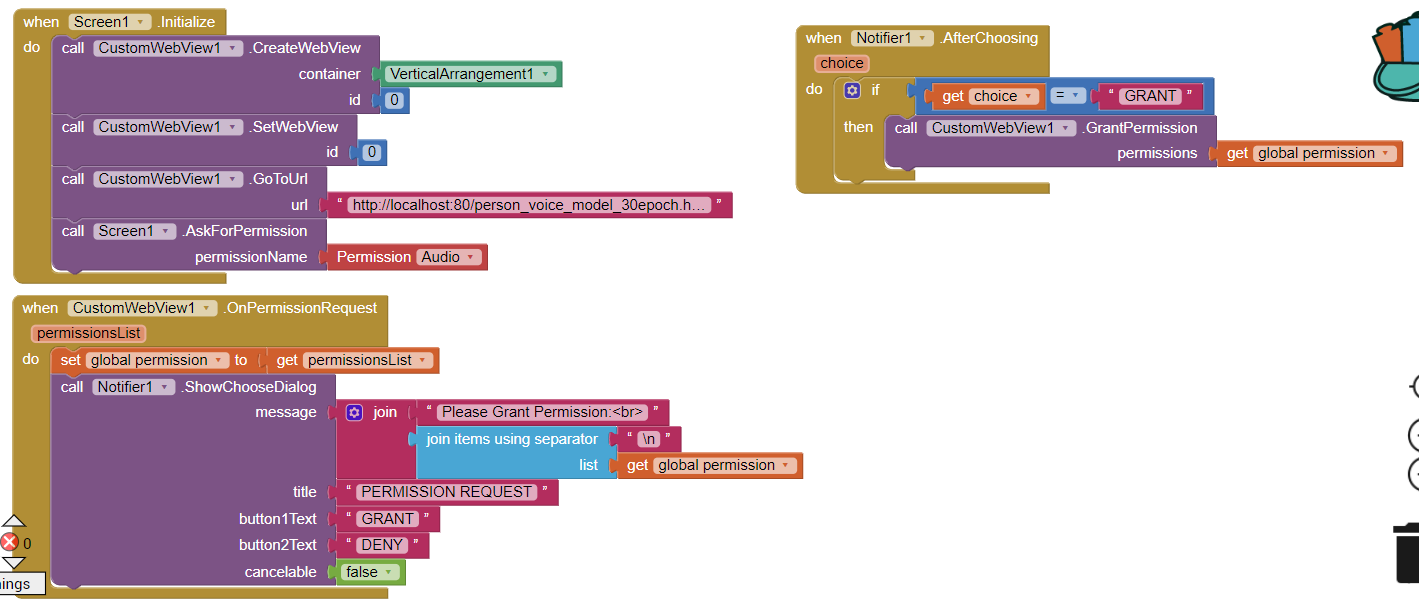
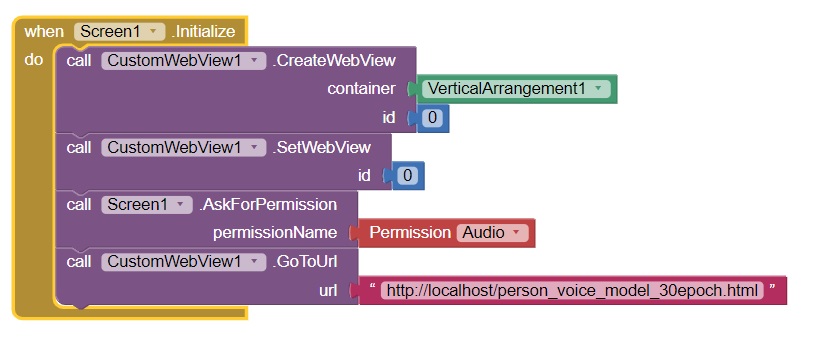
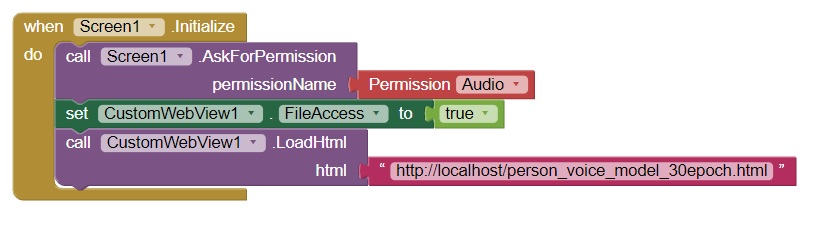
Uploaded the CustomWebView extension. Looked at the forum and followed the steps in the following "thread" (Can't allow microphone access for webviewer - #33 by Anke). Actually I made exact block structure as "Anke" (please see ILL 4 below).
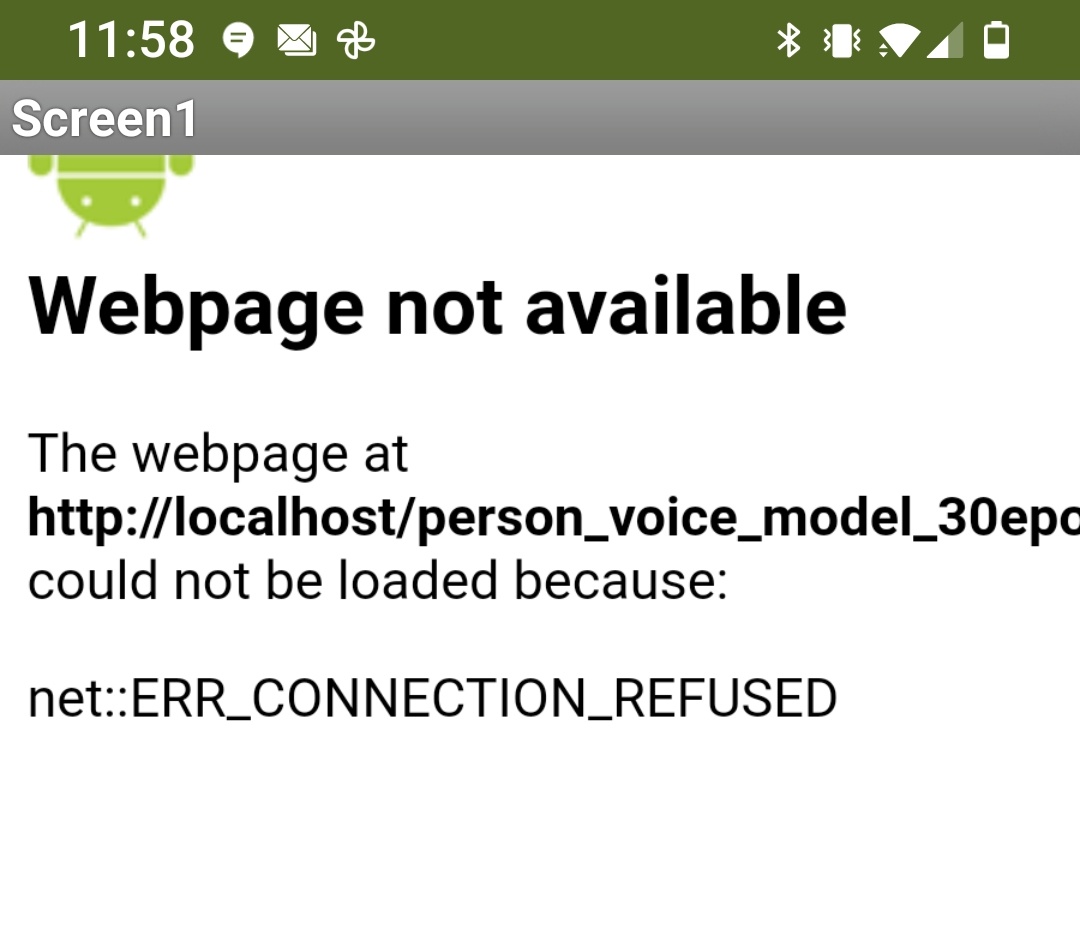
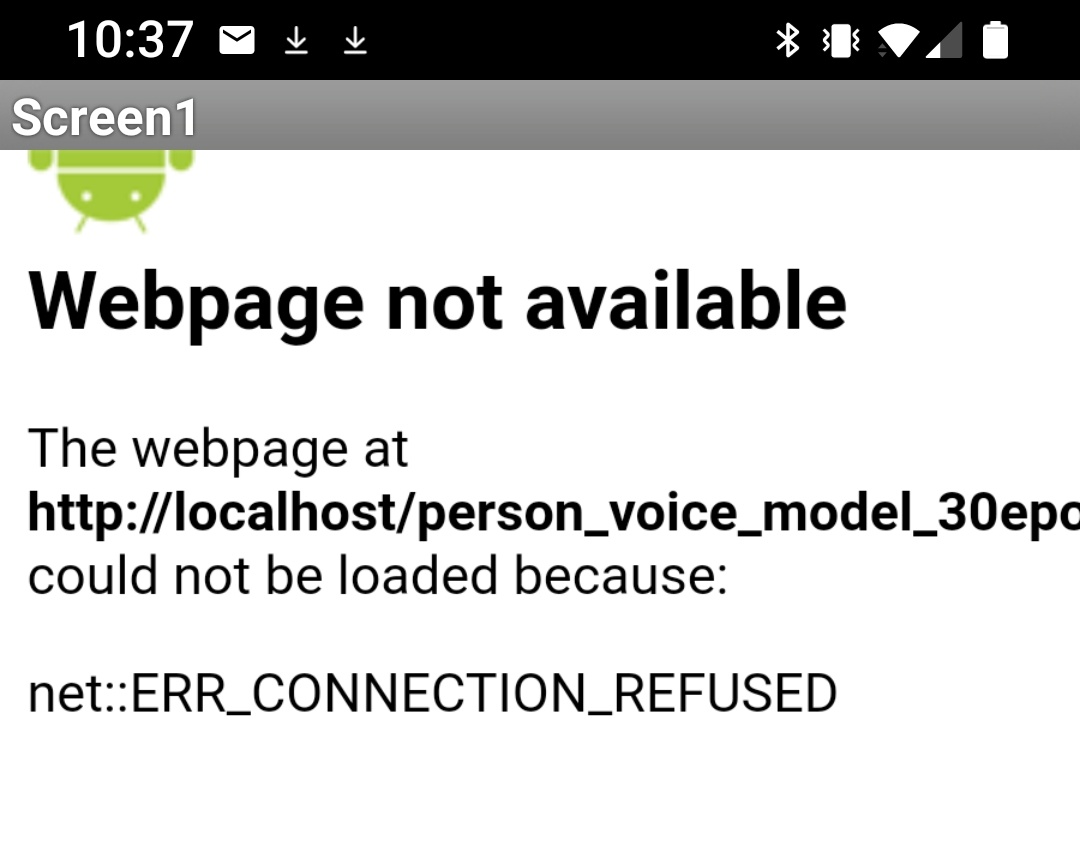
As a result the app throws the error - when it runs on my smartphone (Android 11)(please see ILL 5 below):
"Webpage not available"
"..html file path could not be loaded because:"
"net:: ERR_CONNECTION_REFUSED"
Now that I went over Anke's blocks and comments again, I see her message (ILL6), and am thinking that might be the root cause of what is going on with my trial here: Note : It only works with the APK since android.webkit.resource.AUDIO_CAPTURE is not declared in the Companion app's Manifest.
It is too late tonight for me to try downloading and installing the apk file but will try that tomorrow. If that doesn't fix the issue, I will try something similar to the following post (WebView Javascript Processor) and try providing the approval to use the mic ("audio") by hard-coding it in the javascript (my ML Model snippet) by using:
window.AppInventor.get.Webstring()
and/or
window.AppInventor.set.Webstring()
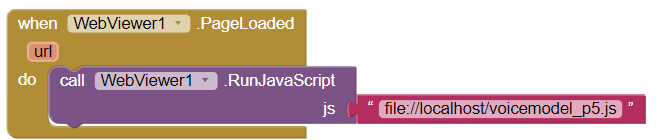
Note: I also tried running the java script (html extension) via "call WebViewer.RunJavaScript" block, with 2 models, one saved with "js" extension and approached as a local "file" and the other with "html" extension and approached as a url / html page, but nothing showed up on the app screen when I run it. (please see ILL 7 & ILL 8)
All the reported behavior (my post thread above) is when I connect the smartphone via bar code to the AppInventor and run the app on my smartphone.
Do you think I should add port number when trying to "run java script" by referencing http ?
Perhaps port 80 ?
When I used standard "web viewer" component, I would set the "home" URL, and use "go home" (if I recall.correctly the "commands"). The app would execute the script (java saved as html) but the request for allowing the use of the microphone wouldn't come up.
That is what triggered my post.
I believe the you do need to use the CustomWebView to get microphone access, and as advised above, you will have to compile your app to test if it works.
OK, the story continues with a limited (if any) success.
Tried 2 scenarios, both using the "CustomWebViewer" and being tested on my smartphone (Android 11) by creating the "apk" file and installing it on it.
Scenario 1
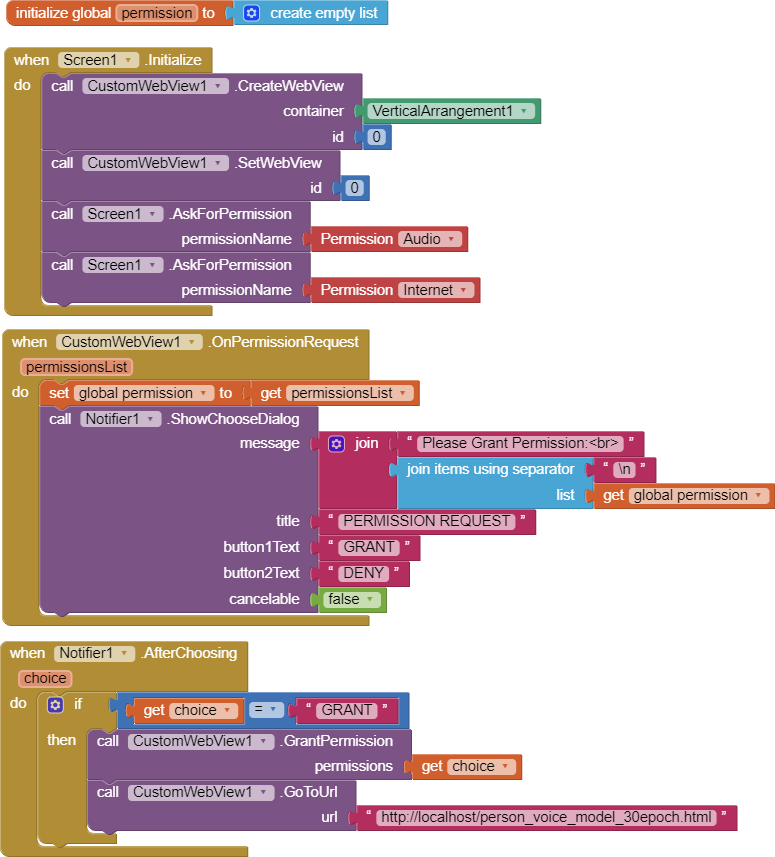
Created a quick block structure, just to learn if the CustomWebViewer will prompt me to allow use of the microphone/audio/recording and it did. Please see the blocks on ILL 9 below
After I allowed (approved) the recording (while using the app), the popup window cleared, now clearly showing Scren1 and a message telling me that access to the uploaded html file was refused (that file is my ML model from TeachableMachine, a p5.js java script, uploaded to the MIT App Inventor as a media asset, with "html" extension). Please see ILL 9B below
Scenario 2
I thought, perhaps one needs to allow / approve the access to a file (html) when using CustomWebViewer so I created the 2nd block structure, used "Call Screen.AskForPermission", with permissions sought for Audio and for Internet (perhaps this is incorrect use of those blocks.,, ?). I was hoping that would allow me granting access to both, the use of microphone AND the access to my html file (my ML Model) with the final outcome of the script uploaded java script (ML model, with html extension) will then run in the browser. Please see those blocks on ILL 10 below.
However, the result was a bit worse than in Scenario 1. There was no popup asking to allow recording, but instead the app went straight to "Screen 1", just sitting there, in an empty, white screen (please see ILL 10A).
This concludes my trials for tonight. Most likely I am messing up something with the blocks in Scenario 2. It would be much appreciated if someone can suggest where the error(s) are.
Thank you
Milan
Made several attempts to create blocks that will ask for recording (audio/mic) authorization and then initiate the model (java in form of a html "media" file.
Attempt with "call CustomWebViewer - gotoURL" didn't yield success. The recording request popped up and after that the app just stayed in a blank Screen1
Attempt with "call CustomWebViewer-LoadHtml" was my next exploration (please see the ILL 11 below). That, at least, initiated the java script but ended up with a Runtime Error (please see the ILL 12 below)
Summary
a) when "WebViewer-go Home" block is used, the Java script runs well, without any need for a permission to access my html "media" file. However, the app stays sitting at a line where it expects some sort of approval to use the mic / recording (which WebViewer can not provide/handle)
b) when CustomWebViewer, is used, I can solicit recording/mic permission from a user & have it granted (the rec request pops up), the app initiates the java script (html "media" file) but the viewer throws the RuntimeError (which did not happen when the "basic" WebViewer was used - see "a" above)
Perhaps I am trying to do something that App Inventor 2 can not provide
Will have to sleep it over..
Thank you all for your help
YES, Thank you Anke !!
It worked flawlessly, automagically
This should resolve the problem of achieving approval for audio recording.
Going to see which of your blocks and how to apply to my use case.
Question: is there any other way to troubleshoot / tests during development except having the "apk" file installed on the device to test (given the Companion's Manifest issue) ?
Milan
Pardon for adding more to the original thread. If needed, I will create a new question post ?
Making changes to my use case by mimicking Anke's work and managed to have my app to work 1 out of 5 times ... Have to admit, ..this is one weird platform... or perhaps there is so much more to it that I don't know.
The app "worked" once, immediately after I installed it for the 1st time, then it didn't. I inserted some control points (because the app can be tested only when installed on the smartphone). However, the app worked once and never again. Now, it cycles through the blocks, hitting control points, ends up invoking the java script but it just sits in it... Seems all is spinning around Permission Requests, their timing or queuing...(if any..)
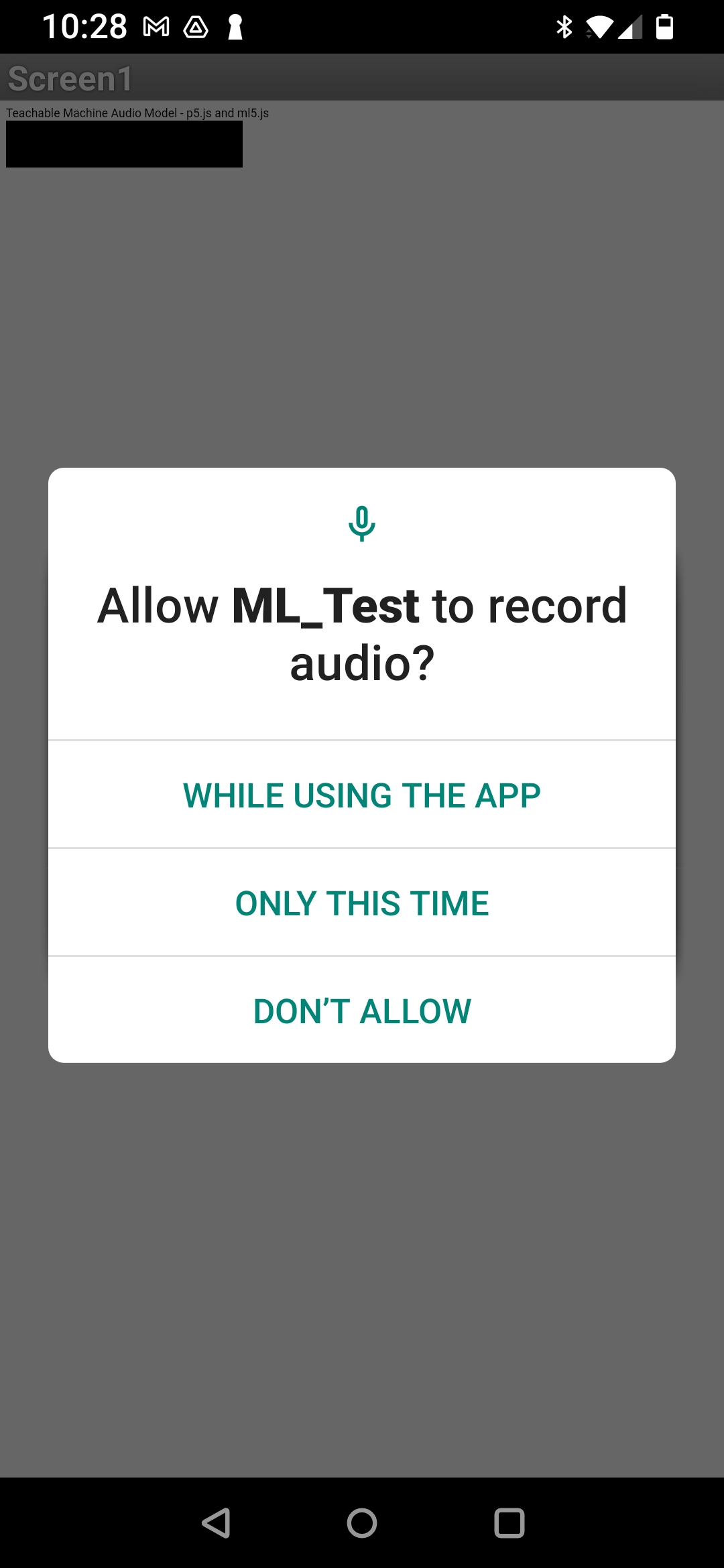
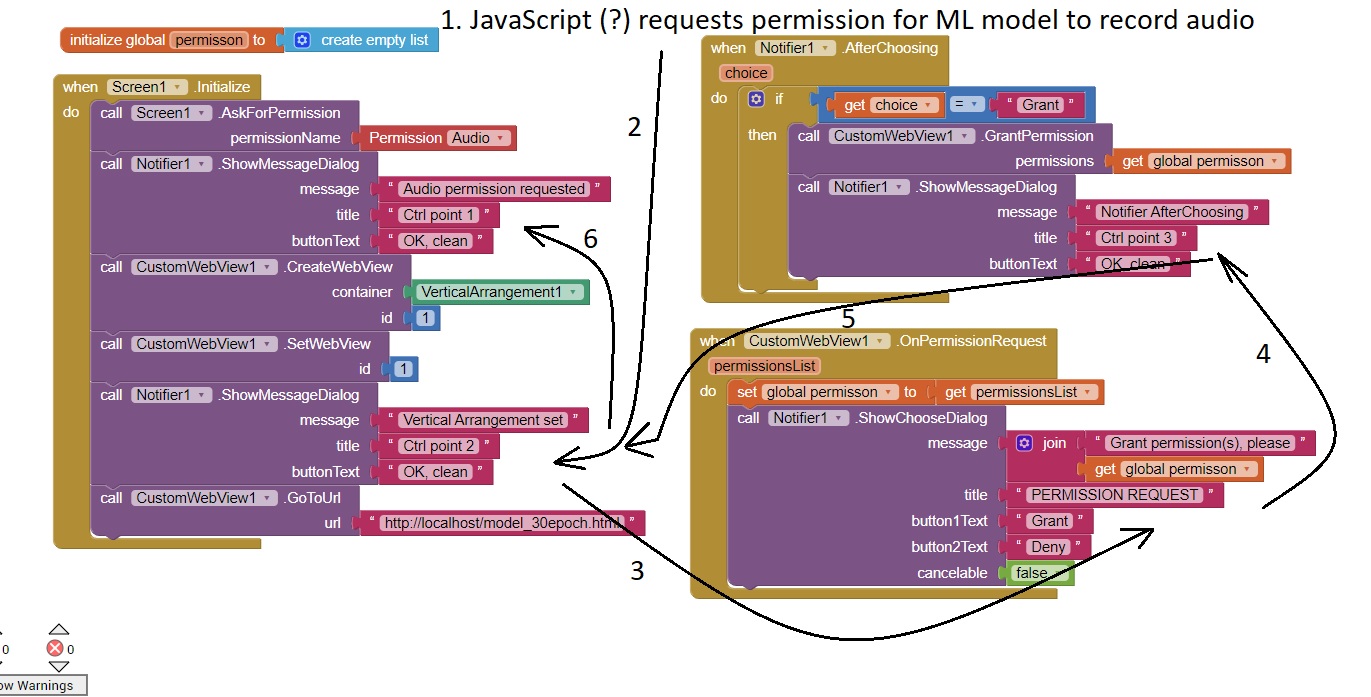
Working Scenario
Installed the apk and after starting the app prompted me to Allow "ML_Test" to record audio (that is the name of my app under test). This popup is unknown to me, or better to say, it is not from my blocks, but perhaps from the Java Script / browser... Also, we can see a black square in the upper left corner of the Screen 1, that is my ML model's screen when running (already ? ). I think it is that ML model (java script) that initiated this screen (below). It showed only once, and that time the model run perfectly (first time). When it doesn't show, the model does not work.
After allowing it (While using App), the next popup was Ctrl Point 2 (I allowed and cleared the screen)
Next the "OnPermissionRequest" popped up and I chose "Grant"
Next popup was Ctrl Point 3 (Notifier screen)
Next was Ctrl Point 2 Popup
The final popup was Ctrl Point 1, after which the ML Model screen showed (black background) and it started showing names of people it was recognizing speaking.
Here is the above flow in an illustration, showing the flow of screens (as I saw them cycling), not necessarily the code flow, but the order how the Ctrl Screens appeared.
At this point I restarted the app to see the process again. This time and later the app did not perform successfully (as described above). Even if I power cycled the smartphone ...
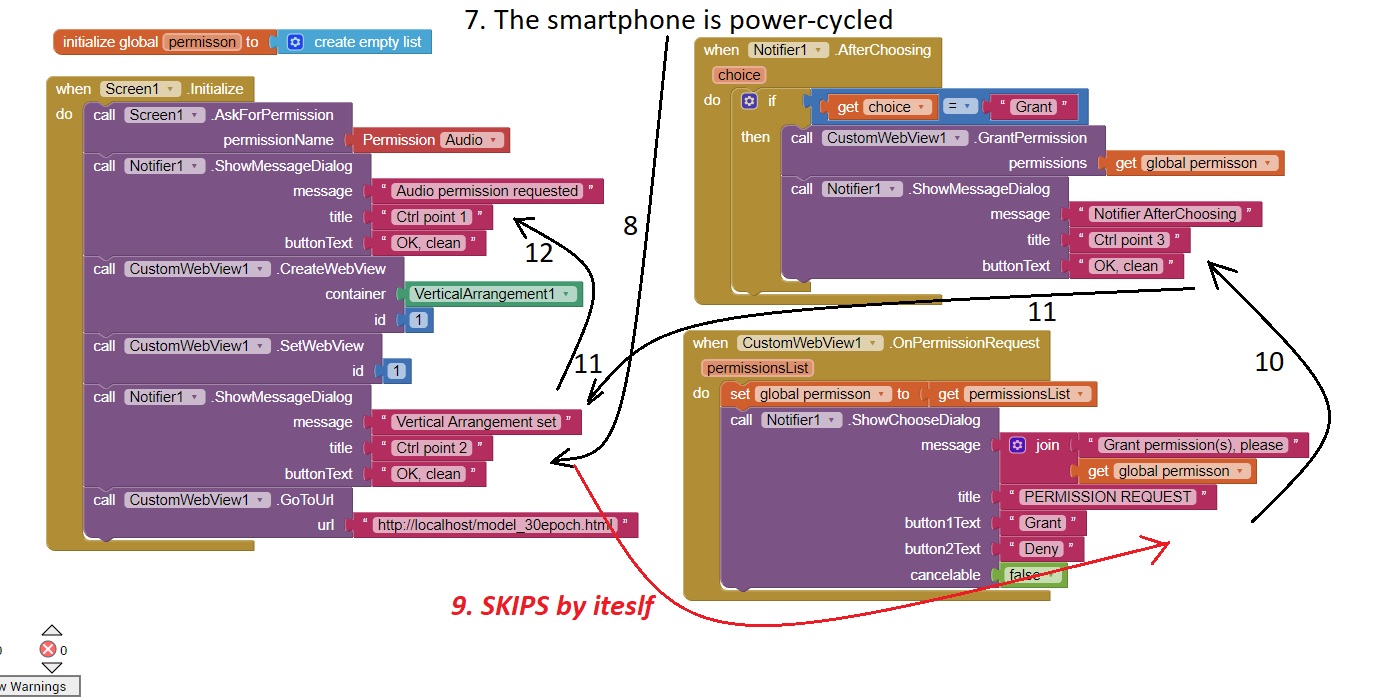
Unsuccessful Scenario
7. Smartphone power cycled
8. First popup is Ctrl Point 2. Before I reacted, the screen changed and next popup showed up ??
9. App skips and props up (w/o my interaction) the "OnPermissionRequest", and I chose "Grant"
10 Next, the notifier CtrlPoint 3 popped up (I cleared it)
11 Next, the Ctrl Point 2 came up
12 Finally, the CtrlPoint 1 showed up
13 After this, I could see the black screen my ML model (java script) renders but it kept sitting without any action. It appears to me the crucial step was step 1 from the Successful scenario, where java script seemed to load a bit earlier than any Permission Requests I coded with the blocks.
So, now I am not sure what to do next... Pretty messy...
Here is the above "fail" flow illustrated (again, the show of screens as I documented them and perhaps not necessarily the flow of the code..?)
It does seem there is a solution but something is telling me the timings of those permission requests is the root cause off all the issues. Pardon for adding more to the original thread. If needed, I will create a new question post ?
Pardon for not replying earlier, several very busy days.
Perhaps I need to rework the whole test (was using backpack, mixing blocks etc).
Will post here when I make some progress. Really am determined to figure out what is going on. Thank you all for your help so far.