I am going through tutorials I will be using with students. I have followed the directions for the voice calculator starter to match the code shared. However, whenever I share a prompt such as "what is 3x5" it shows me what I heard, but then outputs the default response sentence of "I could not understand..." Can someone assist with what I'm missing to have this be functional? Thanks

Dear @SciLASoc,
there are many things that you can do to debug your code.
I see that you display always the sentence "I do not understand..." and you overwrite it only if the split has successuffly found two numbers in the speechrecognizer result.
So what you can verify at first is if the list has two items, then what are the items (you can print them in "temporary" labels).
After the speechrecognizer has shown you what it has understood, are the spaces correctly positioned ? i mean: what(space)is(space)3(space)x(space)5.
At least this is the approach that I would have to debug the code. More steps can arise after this first one.
Best wishes.
Thank you for the information. I built the code based on exactly what was provided in the tutorial, so I'm a little lost on how to adjust this to make it work. I know there are bugs, I'll give it a try, but I'm concerned that the tutorial is incorrect and therefore won't be helpful for students. I'll keep playing with it to see if I can find a solution. Any other workaround ideas will also be appreciated. Thanks again!
1 Like
Can you provide a link to the tutorial?
Some of those are thorns in our sides.
1 Like
So the code in the extractNumbers procedure works by splitting the string at spaces. If you are correct that the speech recognizer is returning "what is 3x5", there are no spaces separating the numbers from the operator. Therefore the returned list would be empty and the path to calculate not taken. Note that the speech recognition is done by a platform-dependent service and so the results vary depending on the operating system and device manufacturer.
I have not been able to test this code as I'm currently in the air, but it should provide a more robust parsing mechanism versus splitting by spaces.
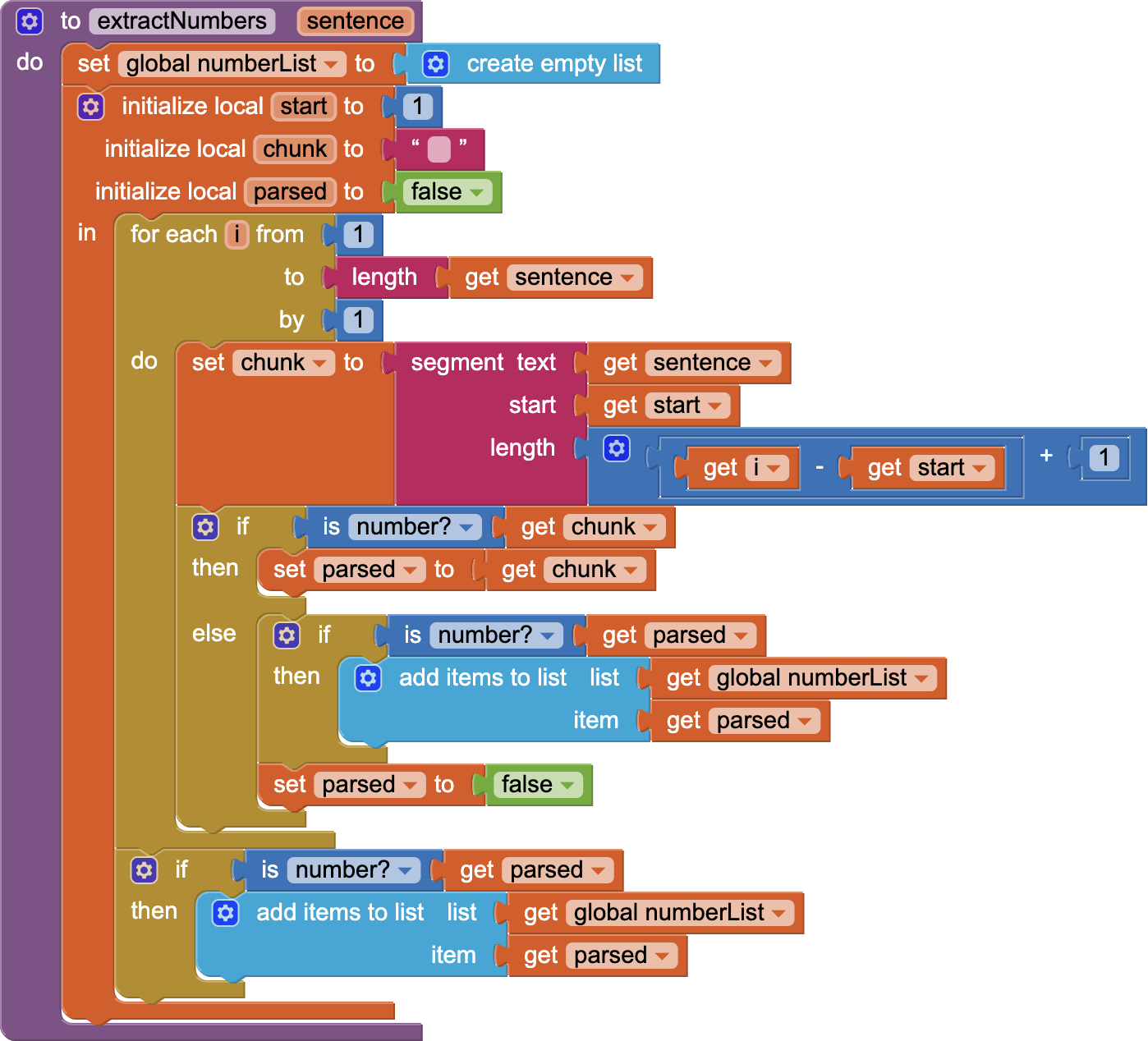
I realize that there was a logic error in my previous post that would result in errors. This version should be better.

I replaced error text (I do not ...) with length of list list>get global numberList and it returned 0, but it does work when I rephrase my question. Saying "what is the product of" worked, while "what is 123 times 85" returns a lenght of 0 (123x85)
(Canned Reply: ABG- Export & Upload .aia)
Export your .aia file and upload it here.
.
No matter what I say, the app responds with, "I could not understand......"
VoiceCalculator_tillitt.aia (119.7 KB)
Hello Darcy @dtillitt ,
The version of this tutorial coded works. You might try it.
VoiceCalculator.aia (119.4 KB)
if the problem is a coding error.
Otherwise, speaking loudly and slowly might help the app to understand you.
Thanks. a bunch, I will!
Dang, I get the exact same result with your code!
Click the Speak bar. Say very loud and slowly " two times two equals"
It hears 2 x 2 and surprisingly results in 4.
Here is a speech recognizer tutorial; you can do it of course but I would like you to follow the advice in the tutorial explaining to its users how to talk to their phone. ![]()