I setup a database on firebase that is quite large, about 315,000 records. This is a list of vehicles by year. In my app I am trying to select the year, then that will show only the vehicle makes in that year. Then you select the model from that. When I was using a smaller test set of data roughly 10 different vehicles, the app was working perfect. I uploaded my full vehicle list to firebase, but now when I go into app inventor, and select year, the app is crashing and closing out. When it does this, I dont see an error created. I have a feeling its a fan of the size of the list its trying to display.
Im not using the actual firebase extension built into app inventor, I am using the web connectivity feature, and then putting in the url for json file from firebase to pull the data. Is there a best practice for working with large amounts of data like Im attempting?
I figured as much. That's the problem I'm going to run into. There won't be a way to know what they may select. So with that, is there a better way to handle the large list locally?
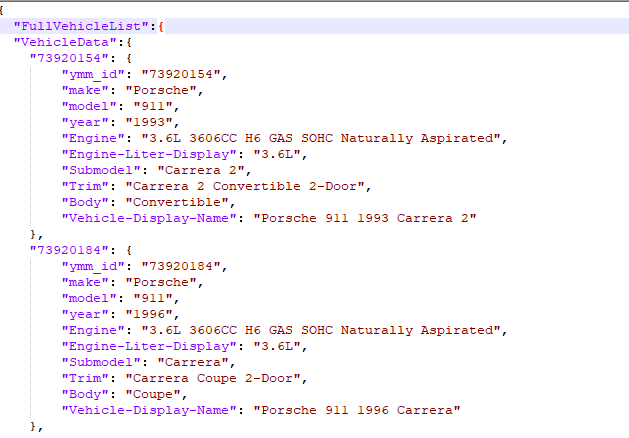
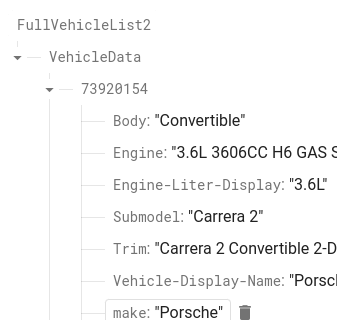
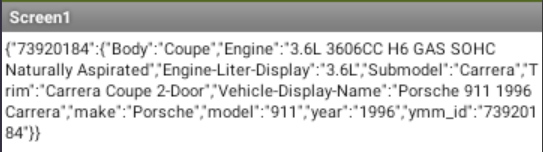
So I am using a walk through in a dictionary. Below is a screen shot of what the got text is doing after the json file is pulled. I read through the data structure things you posted, and how to flatten out the data. With this data set I have Im not sure how I would do that though. Is it something where I would have 3 different "tables"? one for year with a key, a second for the make with the same key, and third with the model, and that same key again. Then link it together similar to what I have the blocks doing now? I have also taken a screen shot of what the json data being stored in firebase looks like.
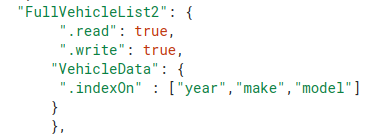
As suggested by others, you need to use the indexing feature in Firebase, get Firebase to do the grunt work of filtering your data, to return the filtered results
Sorry it has taken me so long to respond, the normal 9-5 job has been crazy busy. Firebase gets updated with a json file that I am uploading. I wrote a small program through python that converts a csv file to a json file.
This data may get updated once a year with new vehicles that have been manufactured. So the start of 2024, there would be another upload made appending data to the existing table.
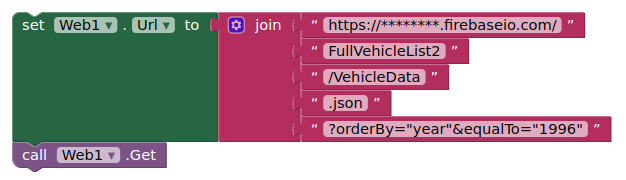
if I try using the below URL in a browser, I get a message that I need to add indexes to my rules. Im not sure if it takes a bit for firebase to build the indexes, or if it doesnt like the way the rules are setup.
Be aware that firebase will not return a sorted set of results.
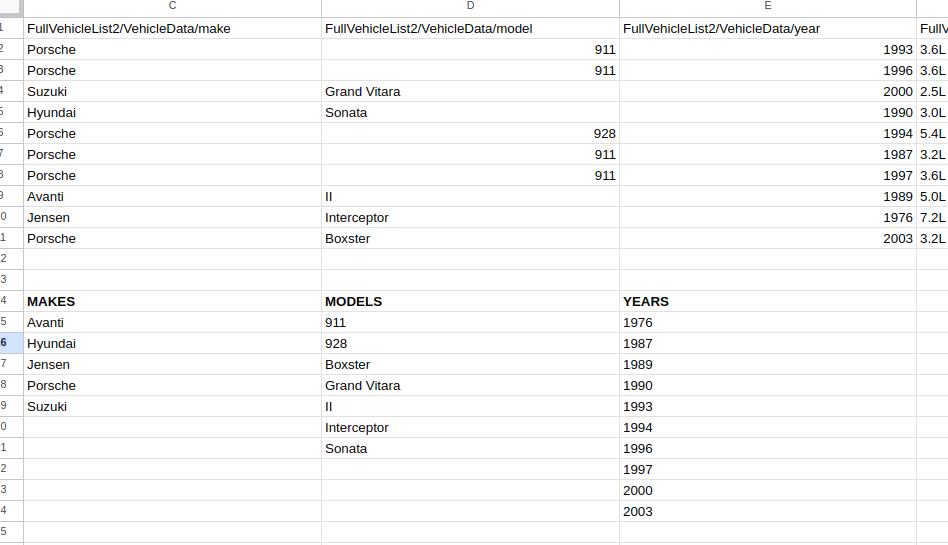
With such a large dataset, I would suggest that you generate lists of years, makes and models from the data on first run, either store this also on firebase or on the device. This will help to make querying the data easier, and avoid having to download all the data to get results.
This could be done by pulling the data into a google sheet and generating the required lists there:
[EDIT] I have just remembered, there is a gotcha to importing the json to a google sheet, it can only handle 40,000 rows, so you would have to split the json into @ 9 files and use 9 sheets!
To be honest, if the data is only updated @ once a year, you might be better off loading the data into an sqlite database and running this locally on each device. This will allow for improved queries and performance.
I got it figured out. the json file is now only 7.43mb. I did some filtering through it. There were duplicate entries based on the model, sub model, and engine size. Also I added some concatenated fields so the year, make and model were all one word in a field. So now you open the app, hit year, and it only pulls the year table. Then the rest api sends a request for the year selected, and will come back with the makes that were build that year. In the app it then joins the year and make, and I used that value to send in the rest api. That concatenated value matches a year and and make in firebase, and only displays the models that are associated with that make for the year selected.
I appreciate all the help. It made me sit down rethink how I have the tables setup, and what should be used to pull that data out. The table sizes are much smaller, more optimized, and its actually doing what I expected.
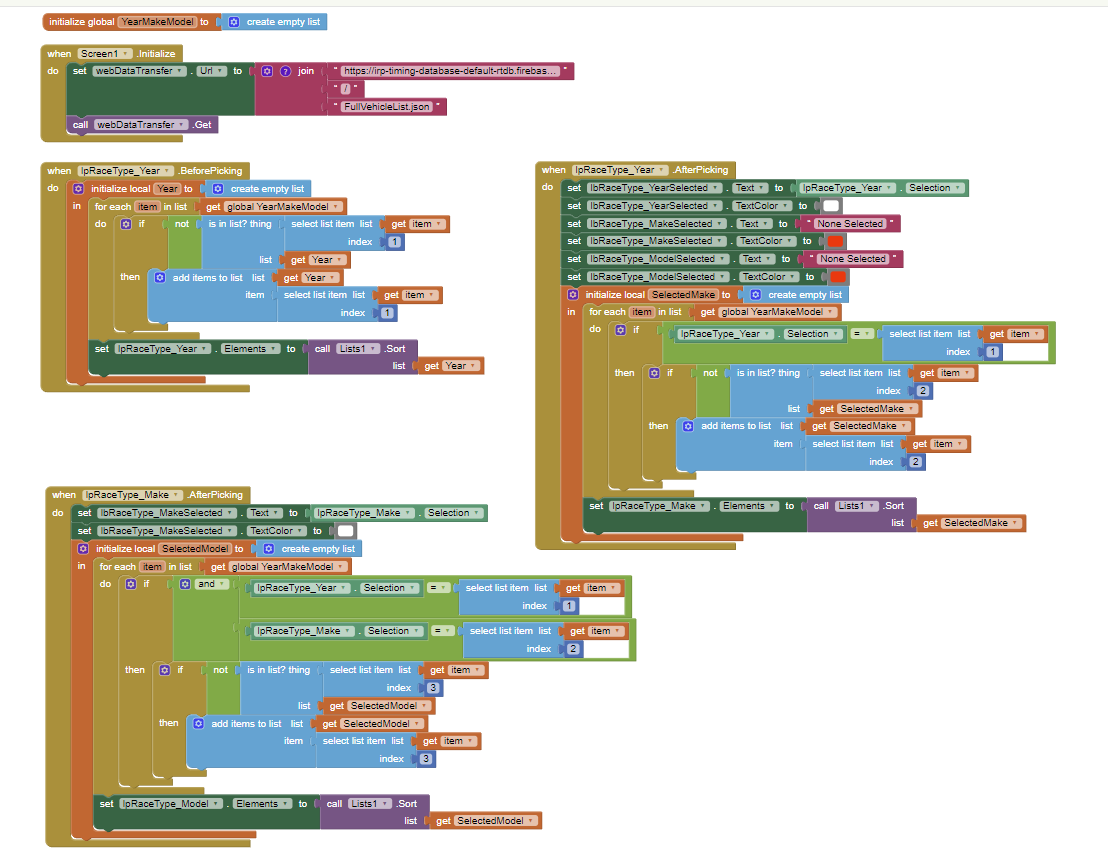
Here are the blocks that I used, and the formatting that was done with the json file that was loaded into Firebase. Ive been testing it for the past couple of hours, and it seems to be pretty stable. Checking it against the data that pulls, and then using the url thats passed to the firebase rest api.