Thank you for your work.
I see there is a description of the blocks, but I still don't know how to use them. Could you please create a sample project that will scrape some data from any page?
I tried something like this but did not work (got html codes but not exactly source code I wanted. It did not get everything on that page and inside of source code there is "please turn on javascript and reload the page" written.)
Thank you for your work. Still a lot of confusion. Can you help me get cricket scores from cricclubs.com, for example, this page: League: WEST INDIES vs IRELAND - CricClubs
I want to display the scores as:
TOTAL:
WICKETS:
OVERS:
TARGET
That web page has a link to download an Excel file.
The downloaded file name ends in .do but it can be opened with a text editor like NotePad++ where it can be seen as just text, with NL line delimiters, comma field spacers, and some tab (\t) line prefixes.
You should be able to parse that download if you proceed cautiously, taking care not to exceed row list lengths after csv table conversion.
Önce Senin Yaptığın Hazır Uygulamayı Denedim Ama Hiç Bir Veri Listelenmedi.
Ne Filim Adı Ne Resim
Bir Fikriniz Var mı ?
"tbody.lister-list > tr" Kaynak Kodlarında Bulamadım.
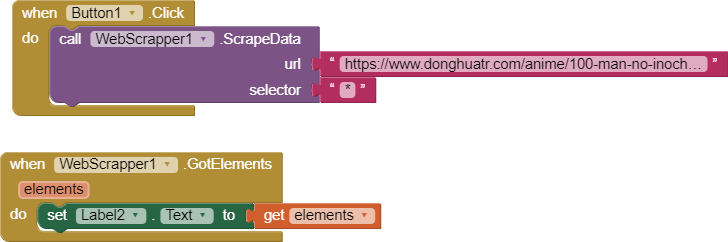
Thanks for your hard work. I tested with the aia file you provided and it doesn't work. You explained about the block but it's a bit difficult to understand how to use it. I think we need a more detailed and friendly guide about web scraper extension.
Hi Tima12,
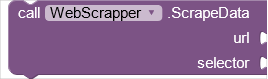
I too cannot get the example (aia) to work - the example webURL is: IMDb Top 250 movies
and the webScrapper1.scrapeData selector is: tbody.lister-list > tr
The URl is a valid one, but there is no 'tbody' element that I can find!?
Can you/anyone suggest a better example to show this working? If I can get it working in example, then I'll soon, I'm sure, get the hang of the rest of the extension!


 *
*