From your image, it looks like your data is between <h1> and <
(It doesn't show more), and its a CSV row.
Here is a procedure to extract (scrape) from web text all occurrences of text between a given prefix ('<h1>') and suffix ('<')
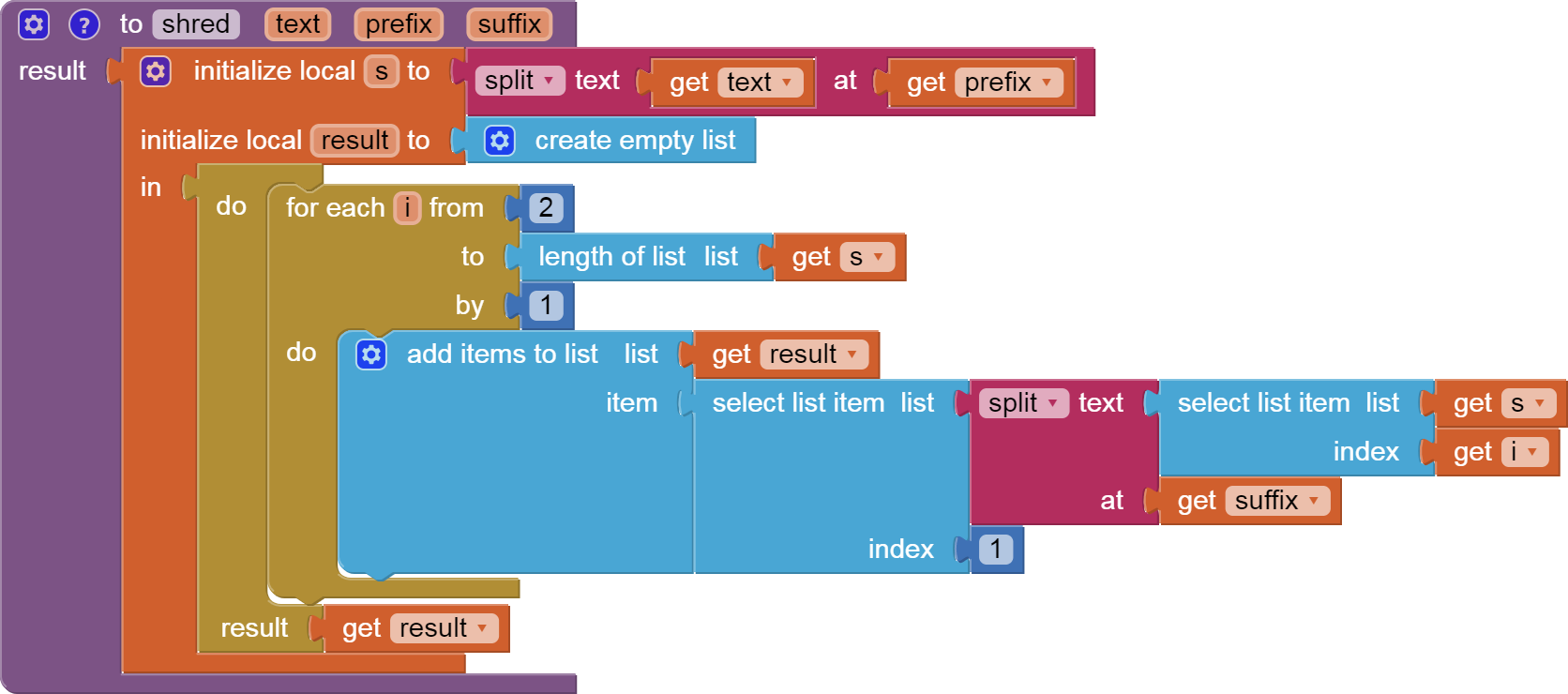
The output is a list, in expectation of finding more than 1 hit, so use the output in a for each loop.
Sample usage: The build server is currently busy. Please try again in a few minutes - #25 by ABG