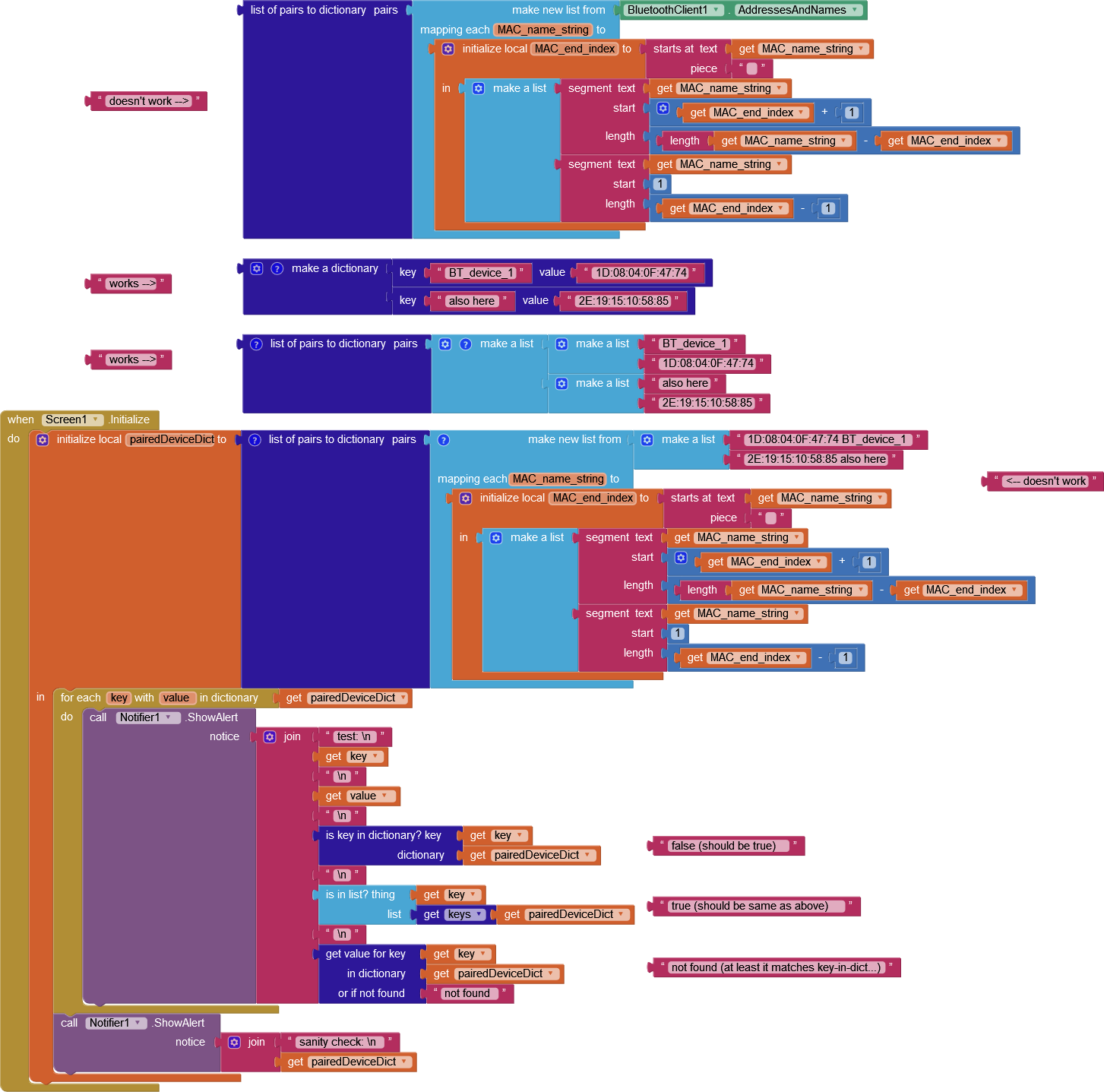
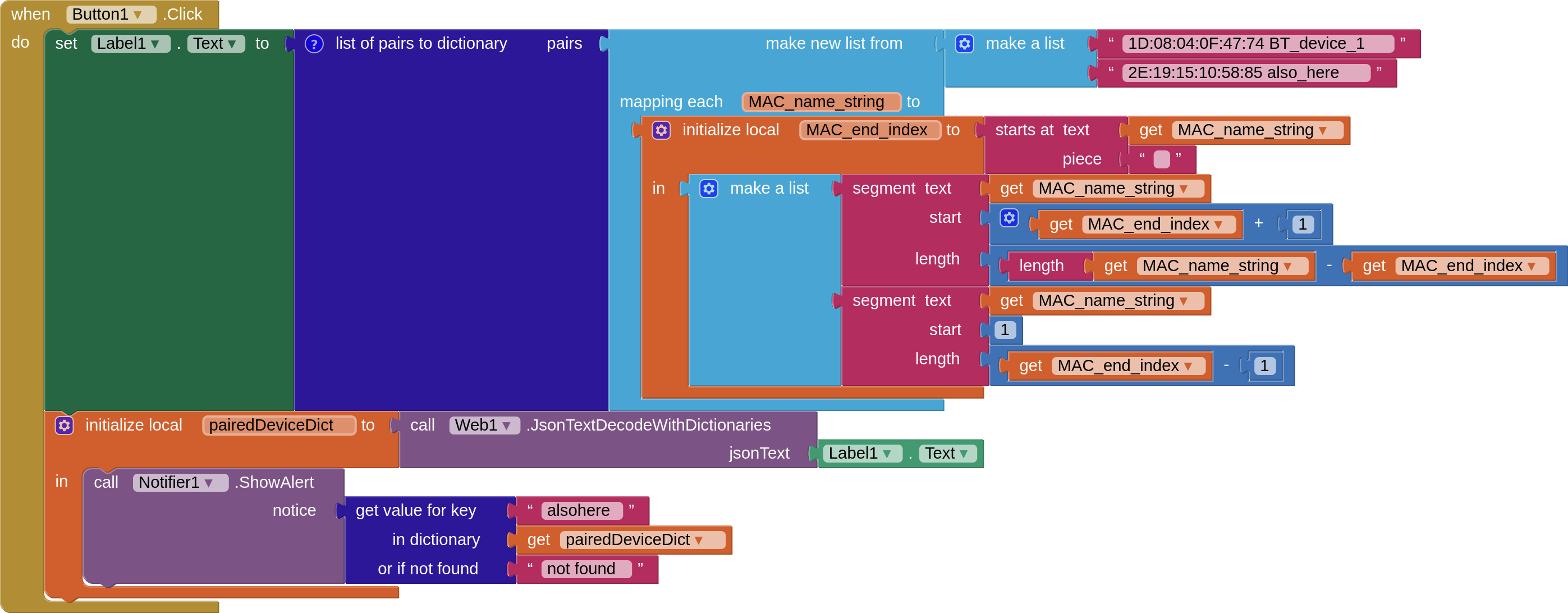
The TL:DR for the blocks above is: when creating a dictionary one way, the values cannot be retrieved, and when creating (what appears to be) the exact same dictionary another way, it works as intended.
I argue that this is a significant issue, because when iterating over the key-value pairs (using the 'for each key with value in dictionary' block), it can't retrieve the value from the dict with that key! If you retrieve the list of keys, it CAN find it in there, but the 'is key in dictionary?' block and the 'get value for key' blocks fail.
The issue seems to stem from the string manipulation used to create the dictionary, but from the 'Do It' outputs, the all dicts look exactly the same:
The new way of initializing the list (to be turned into a dict) does not affect the bug. I've marked the main symptom of the issue on this screenshot, if that helps at all. The 'for each key with value in dictionary' block will produce 'key' and 'value' variables without issue, but when trying to retrieve values from the dict using a key (the dark blue blocks) it can't. The key is absolutely in the dict, as shown by the light-blue list-search check.
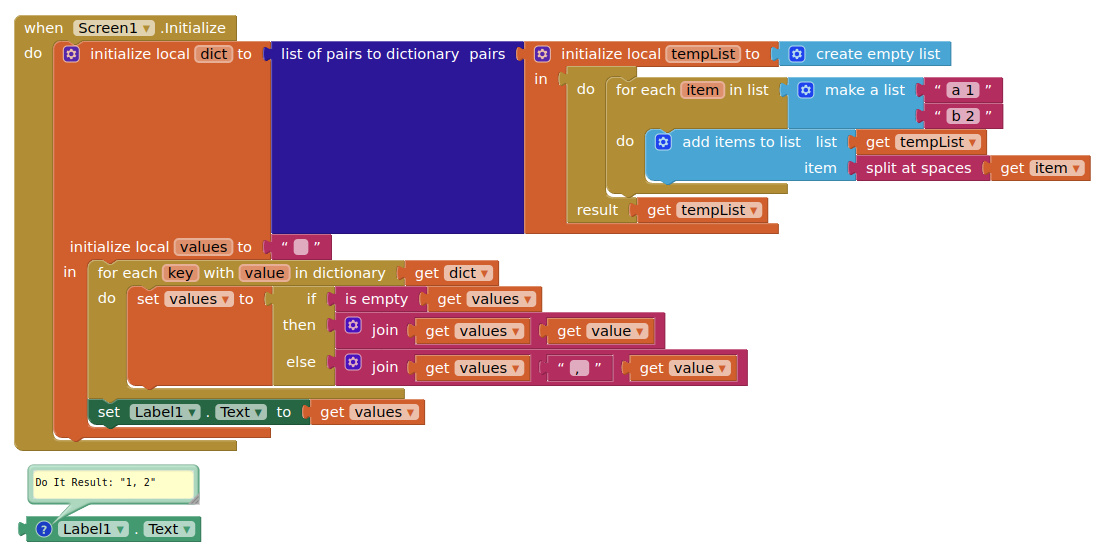
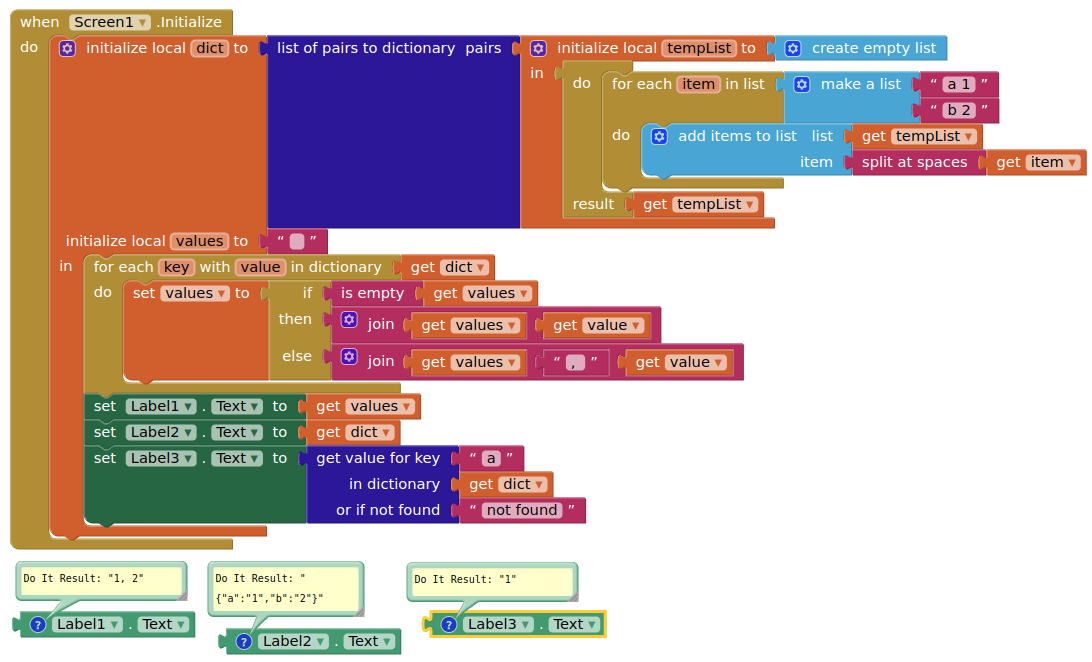
alright, you are correct; when using 'split at spaces', the code works, HOWEVER, when using my blocks of code (which also allows the name of the bluetooth device to have spaces in it), it can produce the exact same strings and lists, but the dicts just won't work:
here is the AIA file: debug.aia (9.8 KB)
if ran, you'll get a notifier alert with the test (see purple blocks in last parts of program)
(edit) P.S. i'm assuming this is an issue somewhere underwater with string conversions & comparisons, e.g. if the dict key is stored as a const char array and being compared to a string (too directly). Either way, with the limited access to underlying types that this visual language allows, i can't find the exact cause.
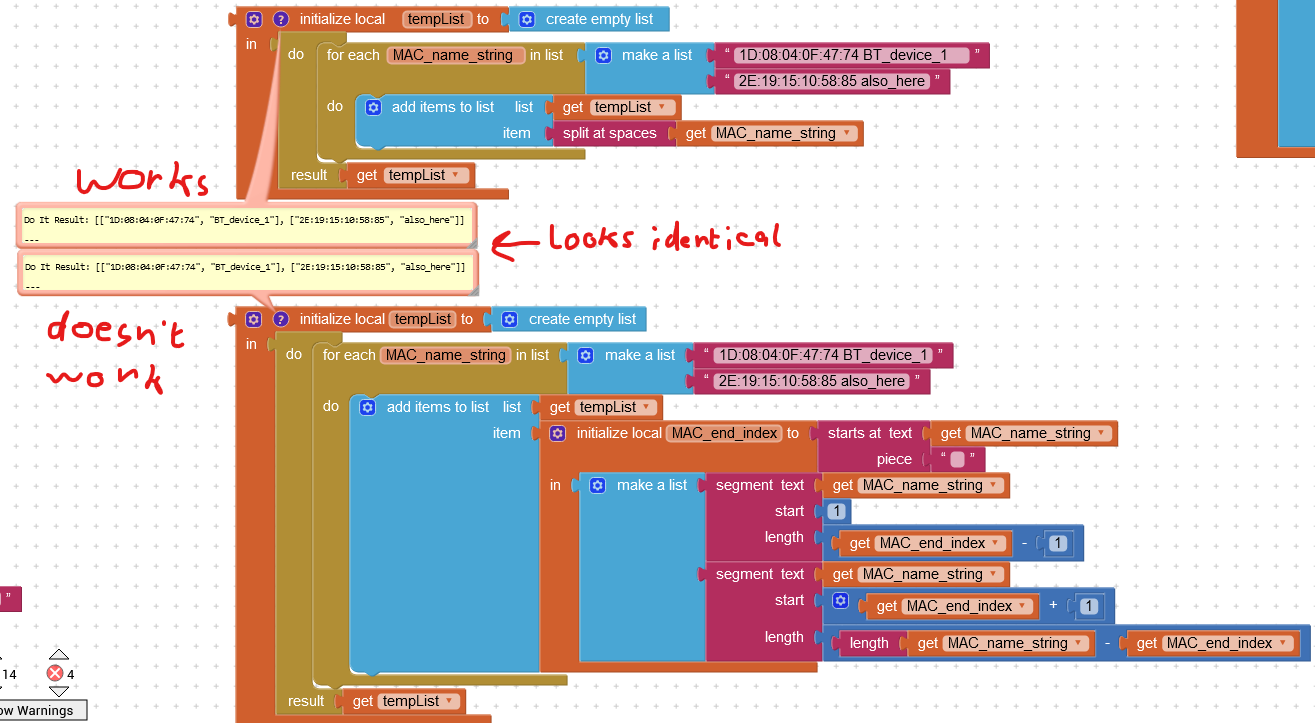
i figured the problem is in the 'segment text' block, considering that 'split at spaces' does work. Either way, thank you for confirming this issue, i suppose it's in the hands of the underlying-infrastructure devs now(?), (or was i supposed to submit a more official report somewhere on github, for example???)
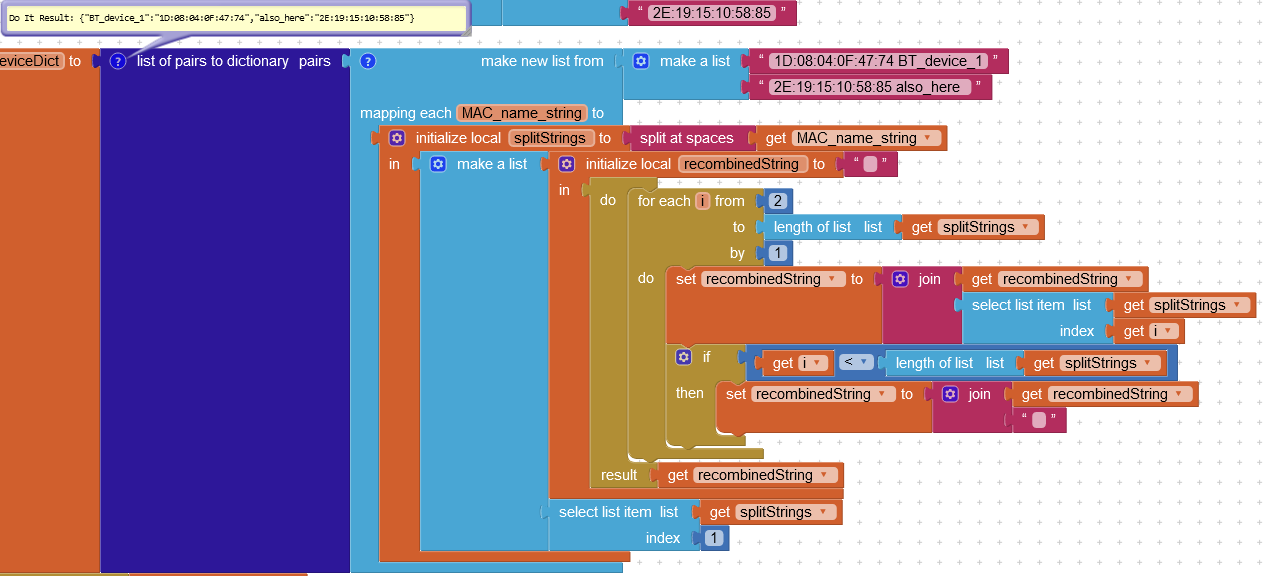
this one is done without 'segment text' blocks and still fails, so that kinda stinks. This monstrosity of join() loops was an attempt to avoiding flattening. I'll look into flat solutions next
adding the 'upcase' block to the key string solves it! (both from 'segment text' source and the join-loops, as long as there is an 'upcase' block in there it'll fix whatever was preventing it from working as a key (i still strongly suspect an underlying type change)
(edit)
GOT IT, the final patch solution:
this fixes the text (makes it suitable for use as a dict key) without altering the text at all
much like my 'upcase' fix, this does alter the text though. If some maniac out there (e.g. future me) wants to have a bluetooth device name end with a space, then i don't want that data to get trimmed off
I looked into this and understand the source of the problem and it has to do with an interaction between a few different things. First, Kawa, the library we use for Scheme on Java, has its own internal type called FString that it will use to try and share string buffers (e.g., by sharing backing buffers). The problem here is that the Java String and the Kawa FString while they hash to the same value don't end up being equal. We have checks to capture this in the YailDictionary class, but unfortunately the list of pairs to dictionary block calls through a constructor of the HashMap class that bypasses those checks. This results in the FString values being stored as keys rather than the Java String equivalents. However, the various blocks like key membership and getting values all will convert the FString to String, breaking the equality. I have put together a patch that will fix this by ensuring that the list of pairs to dictionary block takes a different path that will result in the correct type conversions.
Separately, I would like to point out that some of your logic could be simplified by using the split at first variation of the split block, which saves on having to do all of the mathematics around the index of the first space: