Consider the following table:

Taken from this thread: Listpicker and Google sheets
You may have a table like this in a .csv file as an asset, or exported and downloaded from a Google sheet.
Using ![]() , you can convert your .csv file to a list of lists.
, you can convert your .csv file to a list of lists.
There are extensions to view tables, or you could import your table into a relational table, for which there are extensions, or you could use a web viewer with JavaScript and HTML. But what if you do not want to use an extension, or if you want to search through your table in several ways?
For this purpose App Inventor provides Dictionaries, see MIT App Inventor Dictionary Blocks
However, setting up a dictionary from a .csv table is surprisingly difficult and it is not very straightforward what this dictionary should look like.
Dictionaries in AppInventor can be imported from and exported to JSON. And example which matches what we want to achieve is this piece of JSON:
{
"people": [{
"first_name": "Tim",
"last_name": "Beaver"
},{
"first_name": "John",
"last_name": "Smith"
},{
"first_name": "Jane",
"last_name": "Doe"
}]
}
This example would match to this little table:
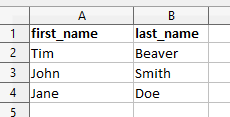
So, our dictionary should become a dictionary with a a single key, which is the name of the table, and as value a list of dictionaries, where each dictionary represents a row in the table, except for the first row which should contain the column names and these are used as keys in the dictionary for each row.
The block that performs this feat looks as follows:
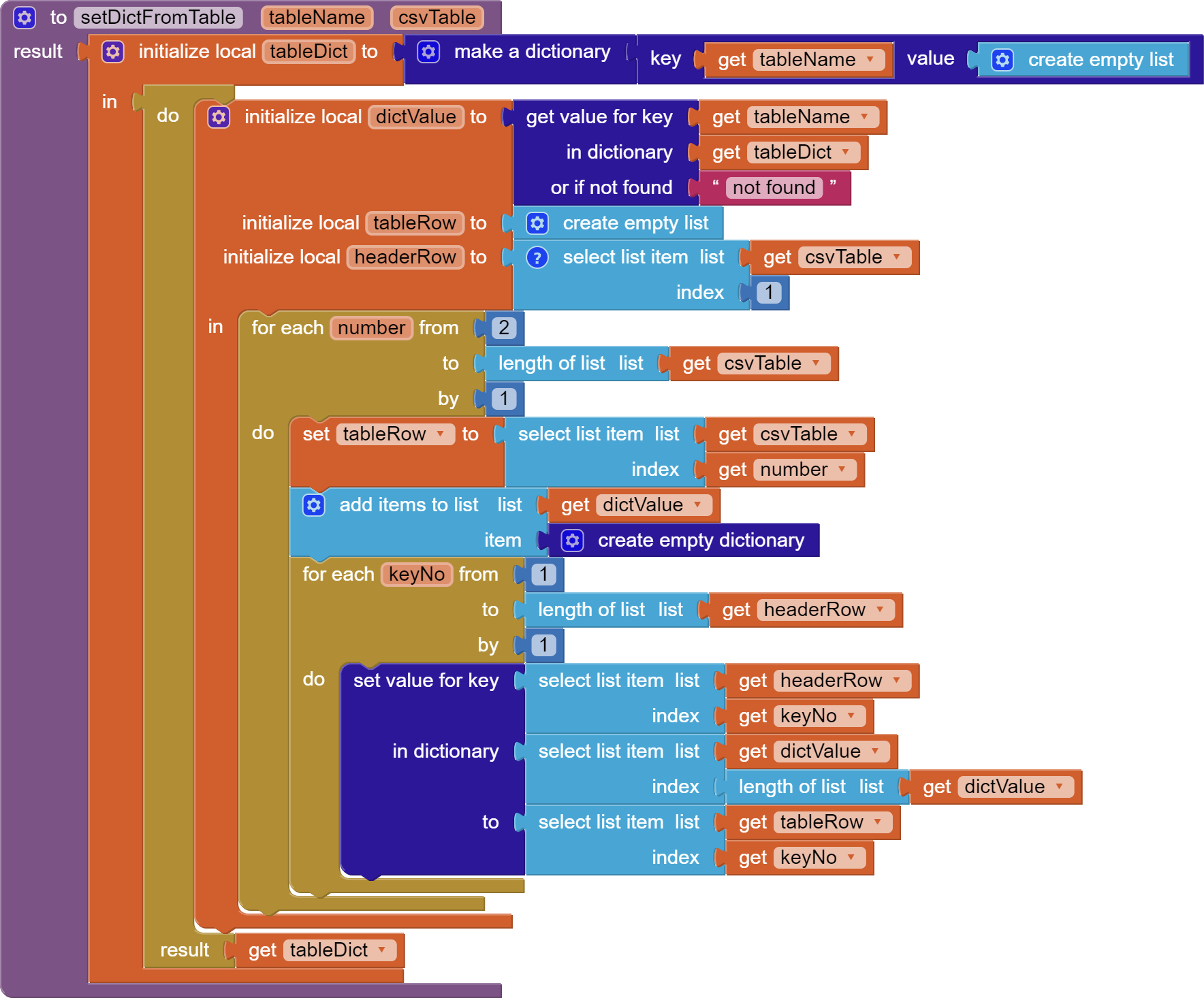
The procedure works as follows:
- It takes as arguments a name for the resulting dictionary table, and a variable containing a list of lists, made from a .csv file, where the first row contains the column names.
- The procedure returns the dictionary as a result.
- First the result dictionary is created as a local variable, with the given name as key and an empty list as value.
- Initalize the keys for each row dictionary by creating a list (headerRow) from the first row of the table.
- Then cycle through the rows, starting at 2, building a dictionary for each row and adding it to the list of dictionaries.
The sad fact, or my lack of comprehension, is, that it is rather difficult to search through such a dictionary. At the first level it has only one key, and for the row dictionaries you can find a list for one column, like this as given in the documentation:
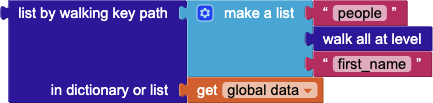
But how to find a list of first names and last names together, or a list of all unique first names?
Back to the example we started with. where we have a table we give the name "Geo" , and which has as column names: "Subtopic", "keyword" and "definitions".
To find the unique list of subtopics, we could use this block:
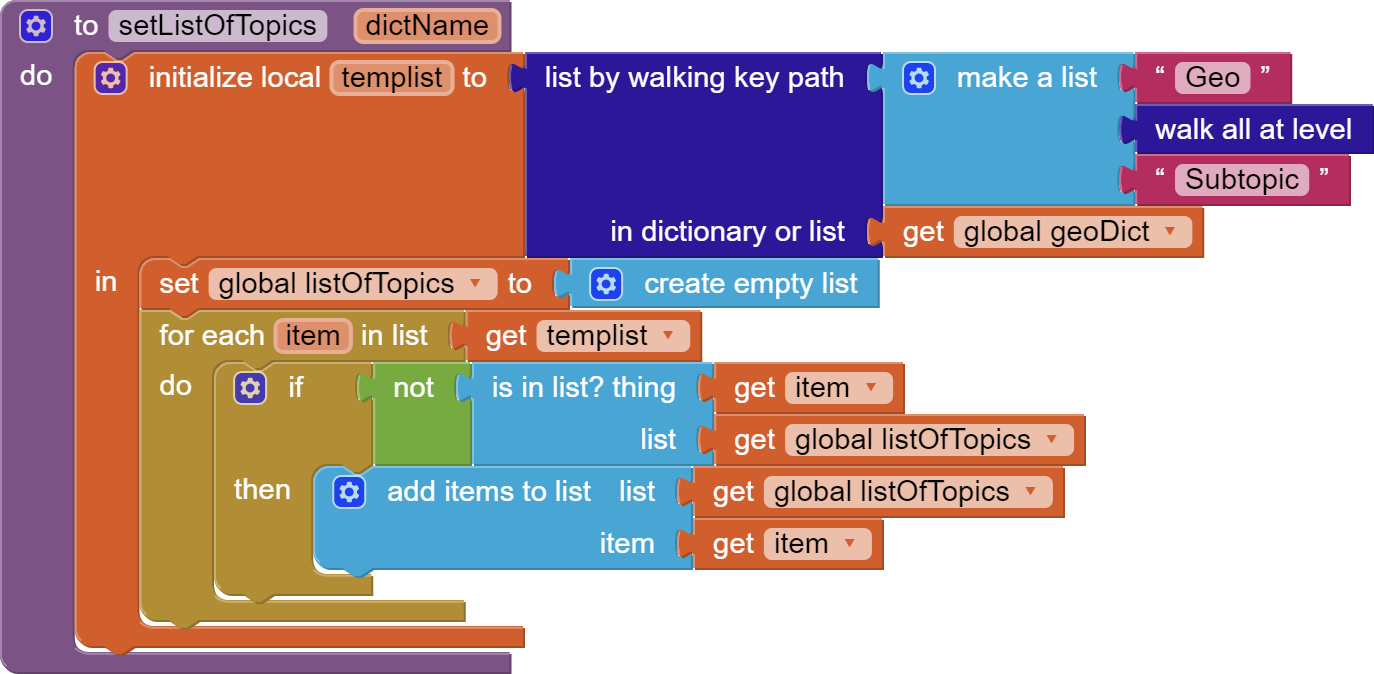
Basically, it finds all subtopics by using "list by walking key path" and then forms a new list by sifting out duplicates.
Another example which is not easy: Assume your app user selected a keyword and you would like to find the corresponding subtopic. The following block will do the trick:
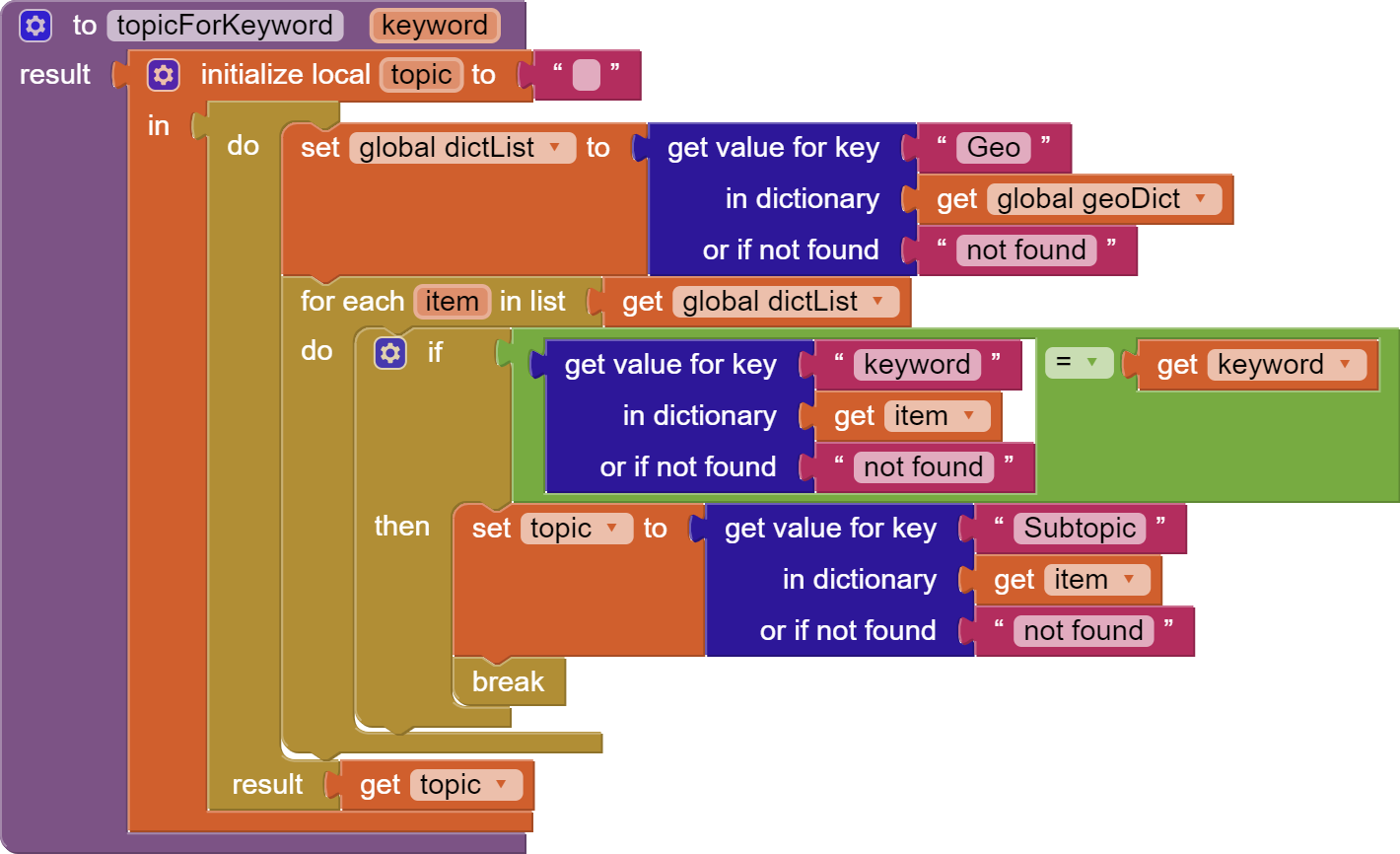
This example is built upon the knowledge that keywords are unique. The procedure goes through the list of dictionaries (each representing a row) and find whether the value for keyword is the one you are looking for. If found you can retrieve the value for the corresponding Subtopic and break.
The attached .aia has a few more queries for this example.
Note that the setDictFromTable procedure is completely generic and can be used for any .csv table that has the column names in the first row.
The other blocks are specific for this set of column names. Probably they could be made more generic too, here they should clarify how to handle this type of queries. I should also add that I tried other Dictionary setups and using the list of lists directly, but none of these were manageable in the end.
Geo_4.aia (8.4 KB)