Greeting. I am new to AI2 and would like to create a simple app to post-process the content of a webpage to extract some info. However when using “call web1.Get” to access the webpage, what the ‘responseContent’ receives is the page source of the webpage, rather than the content that’s presented through webviewer or any web browsers out there. I’d appreciate if anyone can help point me to the right direction. Thanks in advance.
That’s called web page shredding.
Here’s a sample:
P.S. Web Masters hate this.
I will look into that. Thanks a lot for the pointer.
Hi,
I'm looking at trying to do something like this also, but i'm not sure the shredding example answers the question or provides insight into how to scrape text from a page that uses Javascript to populate its content.
There is a web page I don't own or control. Its html code is that returns on a quite sparse and does not actually contain the test I need. i.e. a Web1.GotText "responseContent" does not contain the text I need.
It seems the content is populated using Javascripts, so when I inspect the element when I load the page in a Chrome browser window for example, the text I need is there.
Is there a way to retrieve this text using a similar webscraping process?
You can get webview text using JavaScript.
Try this on your web page in a webviewer:
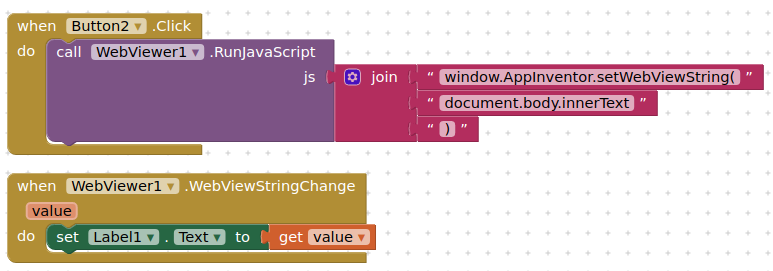
The web page has to be rendered for this to work, so don't run the JS until the page has finished loading (there is a block for that ![]() )
)
This works for me. Thanks a lot. I am trying to scrape the scores from this page: https://www.playhq.com/cricket-australia/org/saca-premier-cricket/junior-boys-summer-202223/ray-sutton-shield/game-centre/50b5e35a
When I use the given code, I can only see the texts from 'Glenelg 1st inning' but the texts from the TAB 'Adelaide 1st innings' stay hidden. How can I display the texts from all the tabs of the page ? Thanks.
test2023.aia (2.1 KB)
Hello Sagar
You have to get permission from the website owners to use their data:
Intellectual property
Unless otherwise identified, all content on PlayHQ, including, but not limited to, text, icons, graphics and the intellectual property rights subsisting in such content, is our property or the property of our licensors.
No part or portion of the content on PlayHQ may be sold, modified, reproduced, transmitted, distributed or used in any manner except as provided in these Terms or with our prior written consent.
To answer your technical query,tThe Adelaide 1st Innings values, whilst buried in the webpage,(you can find them in the page source), are not contained in any inner.Text. You would need to select the Adelaide tab and run the javascript again.
Note the above from @ChrisWard regarding data permissions
Posts regarding web scraping were not allowed I thought .
"No new topics should be started in relation to web scraping"
That's for us to decide, case by case.
