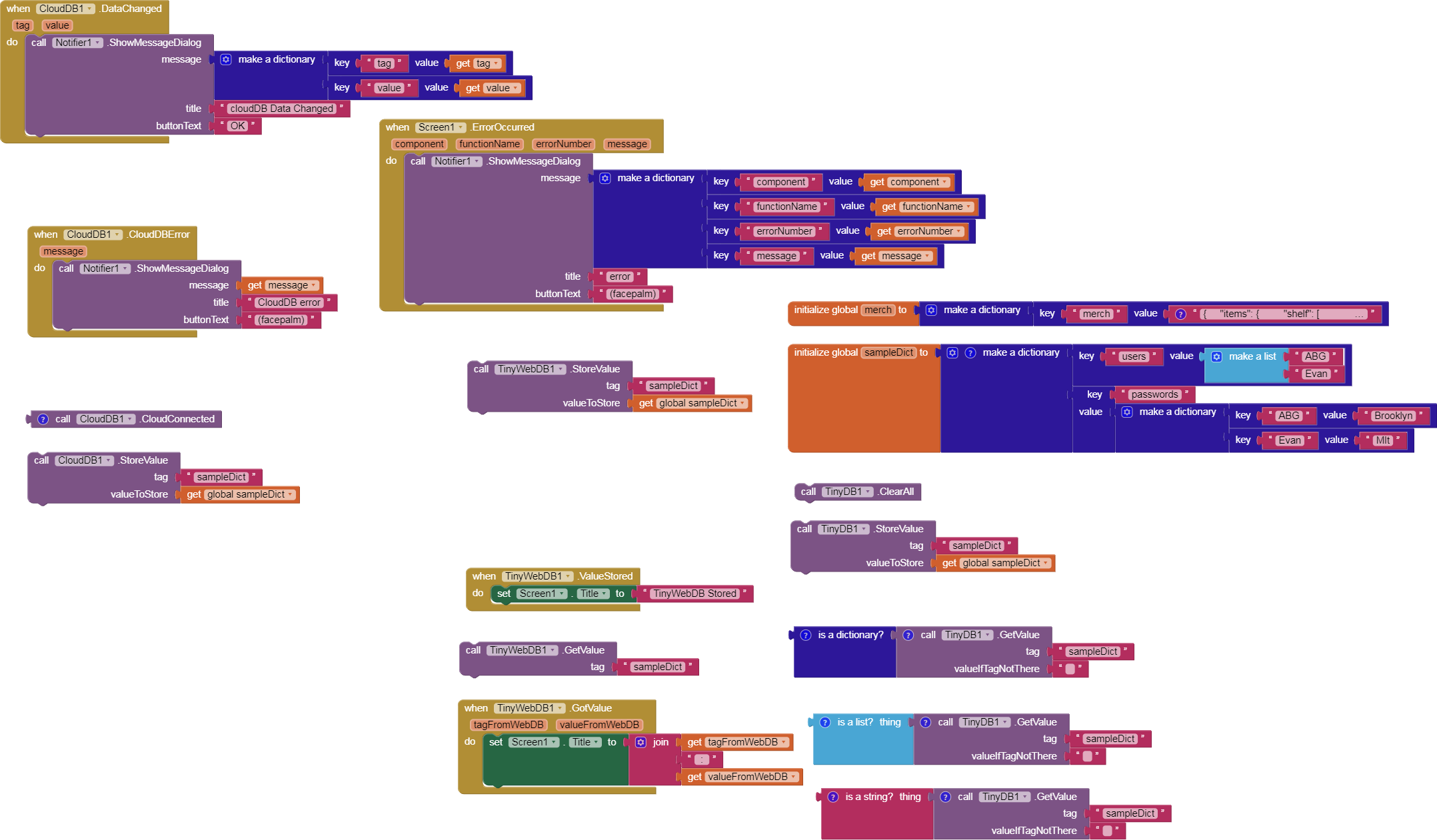
TinyWebDB does not seem to accept or acknowledge requests to store a dictionary.
Sample project:


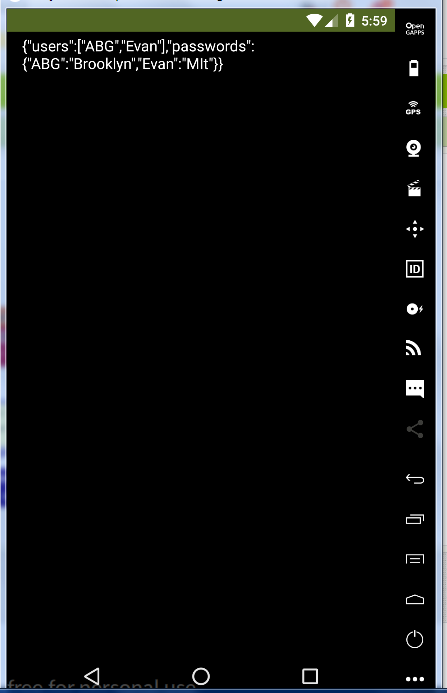
Sample video:
https://www.loom.com/share/2ebbf205cc3d4769925911268817020b
TinyWebDB does not seem to accept or acknowledge requests to store a dictionary.
Sample project:
Sample video:
https://www.loom.com/share/2ebbf205cc3d4769925911268817020b
This might just be the test bed, but dictionaries are not making it into CloudDB.
Sample video:
https://www.loom.com/share/2a220b8e6cfe4943bf19a0a86afcc486
Project export:
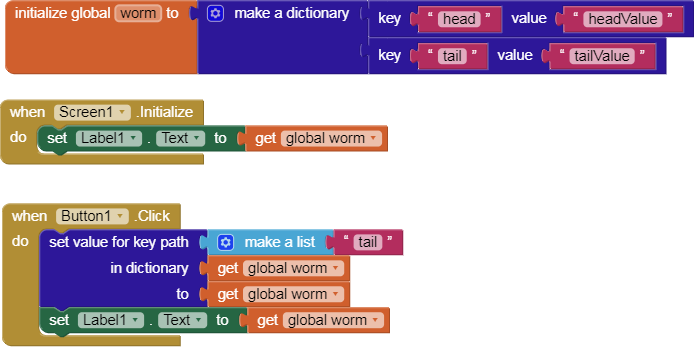
Here’s another key path walking case …
Assign the list output from walking an empty
key path into the Elements of a List Picker …

Should the resulting Elements list have 2 items in it, rather than one item?
Based on how the algorithm is implemented the value is right, which is that it walks the list and at each level enumerates the values at that level before continuing to the next level. It does this until it has an empty list, at which point it adds the value at that point in the tree. In the case of starting with an empty list, it’s as though the algorithm is starting at a leaf so it adds the dictionary itself to the list before returning. However, an alternative approach might allow for an empty key list to yield an empty list, which to me seems like a more palatable result. If you wanted to have a list of each of the values in the dictionary, you’d want to use make a list(walk all at level).
I’m looking into the TinyDB and CloudDB issues. These should work as we have code to both serialize and deserialize dictionaries as JSON and both those components go through that function.
TinyDB worked okay.
Did you mean TinyWebDB?
Yes, I did.
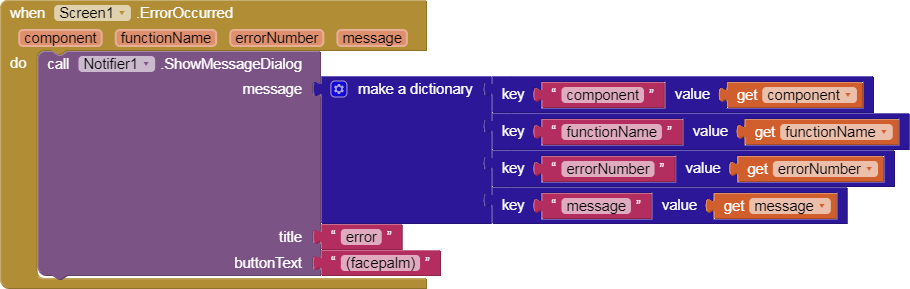
It turns out this was a mix of issues. First, I hadn't configured the test server with our production keys, so naturally Firebase and CloudDB would fail. Unfortunately, there's another issue in that when Firebase fails, it throws an error that interrupts the remainder of components from initializing correctly. Therefore, TinyWebDB1 didn't exist as a registered component and so all events to it are dropped. I've since added the complete configuration and the associated issues should be resolved.
I've also included a new version of the companion with version number 2.55d5 (or 2.55d5u) to differentiate it from our production version.
After thinking about it a bit more, I do think I want to keep the behavior as is rather than implementing my proposal to have it return an empty list instead. My reasoning for this is the block returns one or more elements for the given key path. An empty key path leaves you at the root of the tree represented by the dictionary, so that should get selected. With this implementation, an empty list indicates that nothing existed at the given path. If we were to make it so that an empty key path also returned an empty list then there would be an ambiguity as to what the return value represents.
Regarding large dictionaries for people doing language research
like https://docs.google.com/document/d/1TRGypmOaRvK37oazCuaGBdXzvt4dzzGXaHYvp22ueCs/edit?usp=sharing,
is there a way to to take advantage of dictionary lookup speed (I hope) without suffering
repeated startup lag to undergo text to dictionary conversion on load?
I don’t see any csv to dict block, for example, nor any read/save dict to/from file blocks.
I exercised the FireBaseDB, CloudDB, and TinyWebDB storage and retrieval of dictionaries,
and they all came back as dictionaries.

In passing, I noticed that an empty taglist does not trigger a .TagList event in FireBase.
Since dicts serialize into JSON when coerced to a string, you could just write one to a file. After reading it back, you'll need to use JsonTextDecode to turn it back into a dictionary. TinyDB et al. will serialize/deserialize dictionaries directly as well.
I wrote a small test app to test this (it also revealed some performance issues, which I've fixed in 2.55d6). Here's an example of the data I get from one run with 20k total entries and 1000 random accesses:
Time to create database: 2372 ms
As dictionary:
Time to write to file: 99 ms
Time to read/decode from file: 95 ms
Time to write to TinyDB: 130 ms
Time to read from TinyDB: 287 ms
Time for 1000 random accesses: 186 ms
As associative list:
Time to write to file (CSV): 1178 ms
Time to read from file (CSV): 509 ms
Time to write to TinyDB (CSV): 1224 ms
Time to read from TinyDB (CSV): 483 ms
Time for 1000 random accesses: 26785 ms
DictPerfTest.aia (74.6 KB)
Dictionary to and from JSON speed tests look good for file storage.
I tested 3 corner cases for JSON conversion:
empty dictionary,
No surprises in the first 2 cases, and a can of worms left closed in the null case.
I’m glad I did not name any of my kids “Null”.
Yes, it’s always been our policy to not expose actual null anywhere in the blocks if we can help it (if we do, it shows up as *the-null-value* to help us differentiate it from the string “null”). Both old and new JSON decode methods coerce null to "null", which isn’t ideal, but we’d rather not have to have people reason about null in the blocks language.
I finally got around to trying the walk at all levels block.
It won’t dock into the path socket of the list by walking key path block.

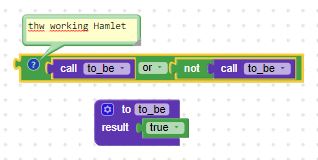
Reminds me of Hamlet;
Hamlet.aia (1.3 KB)
Video:
the working Hamlet ![]()
Taifun
Arguably, Hamlet was expressing an exclusive or, otherwise he’d have his answer without needing to spend so much time expounding about the question.
(spoiler: the answer is true)
This is not a bug report, just an experiment to expose the dictionary internals.
The dictionary values are links, not copies.
Sample project:
Ouroborous_dict.aia (2.1 KB)
Blocks:
It’s getting harder to diagnose misuse of structures when the JSON encodings and decodings look identical in Do It bubbles and coerced text outputs. For example, how to interpret this DoIt value:
{“user”:“ABG”,“score”:0}
If it just text, newly arrived from the Web, or is it a dict or list of pairs coerced by the Do It facility to text?
To aid debugging, can the Do It type coercion facility add background color to its output for structures, following the block colors of the appropriate types (light blue=list, dark blue = dict), based on the pre-coercion type?
Alternatively, consider a monospace ASCII art rendition of the given structure, each item wrapped in a box of +=-| characters, connected by ±|<> arrows. (I’m not sure how to lay this out, to cover back-references.)
I think you mean syntax highlighting in the DoIt result bubble
If memory serves, this is only true when ShowListsAsJson is false. When ShowListsAsJson is true, strings have double quotes around them.
On the one hand, there is some value in not quoting the string because I expect that novice users might consider the quotes to be part of the string. For example, if you use Do It and get back "abc" (versus the unquoted abc), it's possible that you as a novice might think that " is the first character, a is the second character, and so on, whereas such ambiguity doesn't exist if the value isn't quoted. On the other hand, it introduces the ambiguity when dealing with potentially more complicated structures.
I'm not sure that I agree with the proposed use of color to disambiguate. My primary concern being issues around color blindness. It seems like it would be better to include the type information in the text, such as by quoting.
After sleeping on the problem, I have a simpler proposal …
Have the Do It facility test the type of its input.
If it is a text value, wrap it with quotes.
If it is a structure (list/dictionary) serve it up as
JSON or Scheme list (leading character { or ( respectively.)
or whatever the Screen1 ShowListsAsJSON attribute wants.
That would unambiguously distinguish between structures and text impostors.
I would steer clear of GUI-directed text coercion, because that would
break apps.