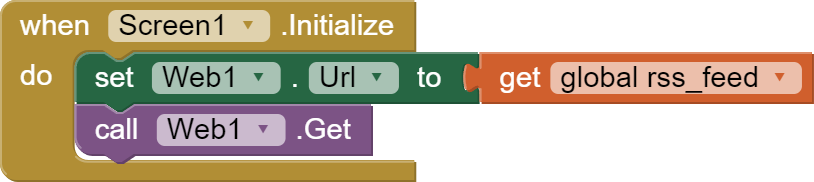
Hello. I got an xml file from this address: Radio Galileo
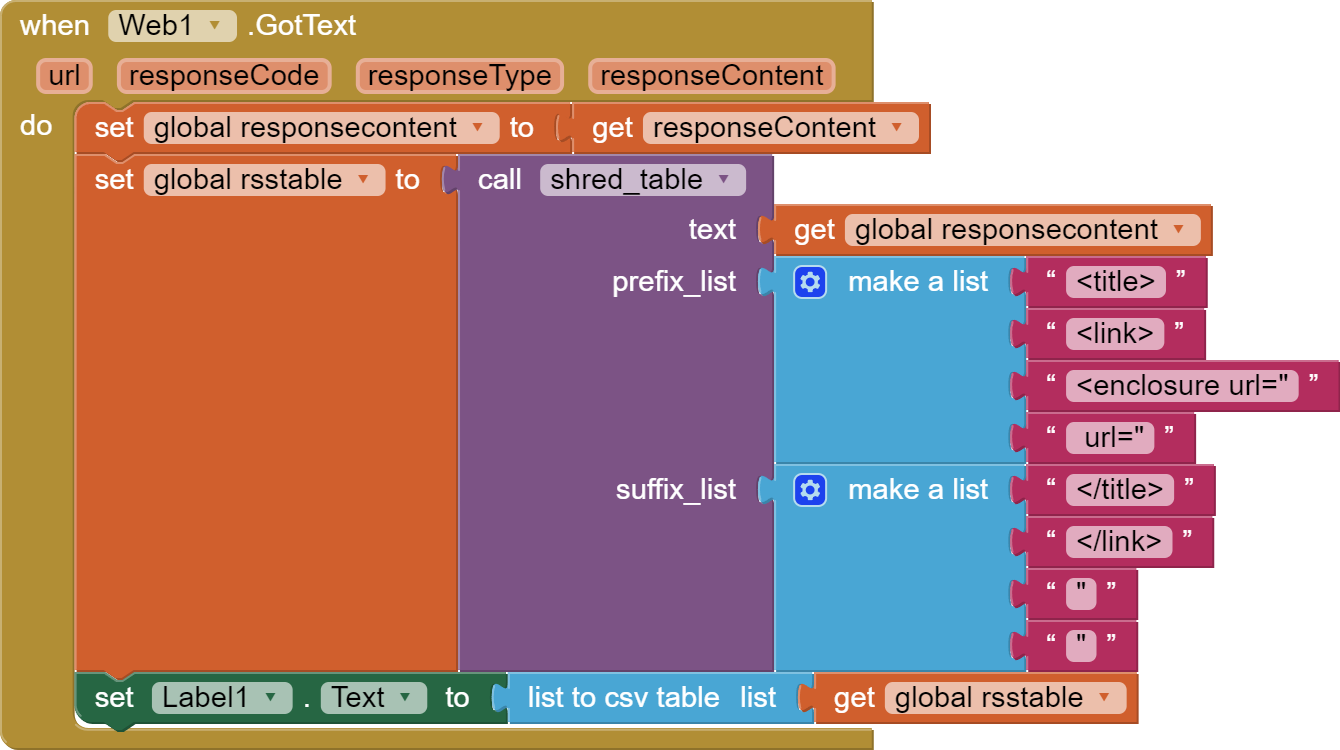
that returns all the news of this local radio station, and i wish to extract "title", "link", "enclosure url" (or "media:content url") from each "item" in the xml file.
I can download the file, but have no success in parsing it. Nor with list pairs nor with dictionary.
And if i decode it with the web1 functionalities for xml file i lost the <> and all the outoput text became a mess...
Hmm - problem is, the file has no consistency. Some items have 'enclosure url' and a 'media:content url' for example.
<item>
<title>Anche l’umbria al campionato quarta categoria figc salute mentale</title>
<link>https://www.radiogalileo.it/sport/2022/10/05/140049-anche-lumbria-al-campionato-quarta-categoria-figc-salute-mentale</link>
<comments>https://www.radiogalileo.it/sport/2022/10/05/140049-anche-lumbria-al-campionato-quarta-categoria-figc-salute-mentale#comments</comments>
<pubDate>Wed, 05 Oct 2022 10:17:57 +0000</pubDate>
<dc:creator>Redazione Galileo</dc:creator>
<category><![CDATA[Attualità]]></category>
<category><![CDATA[Sport]]></category>
<guid isPermaLink="false">https://www.radiogalileo.it/?p=140049</guid>
<description><![CDATA[Il debutto ufficiale in campo è fissato per il 15 ottobre a Pontedera, ma indipendentemente dalla partita, hanno già raggiunto un grande risultato: portare sul campo di calcio ragazzi e ragazze umbri con disabilità mentale per disputare un torneo nazionale. L’iniziativa è dell’Asd Ellera Calcio che con il contributo della Comunità di Capodarco di Perugia…]]></description>
<wfw:commentRss>https://www.radiogalileo.it/sport/2022/10/05/140049-anche-lumbria-al-campionato-quarta-categoria-figc-salute-mentale/feed</wfw:commentRss>
<slash:comments>0</slash:comments>
<enclosure url="https://www.radiogalileo.it/wp-content/uploads/2022/10/coletto-e1664966378932.jpg" length="1089560" type="image/jpg" />
<media:content xmlns:media="http://search.yahoo.com/mrss/" url="https://www.radiogalileo.it/wp-content/uploads/2022/10/coletto-e1664966378932.jpg" width="3590" height="2970" medium="image" type="image/jpeg">
<media:copyright>Radio Galileo</media:copyright>
</media:content>
</item>
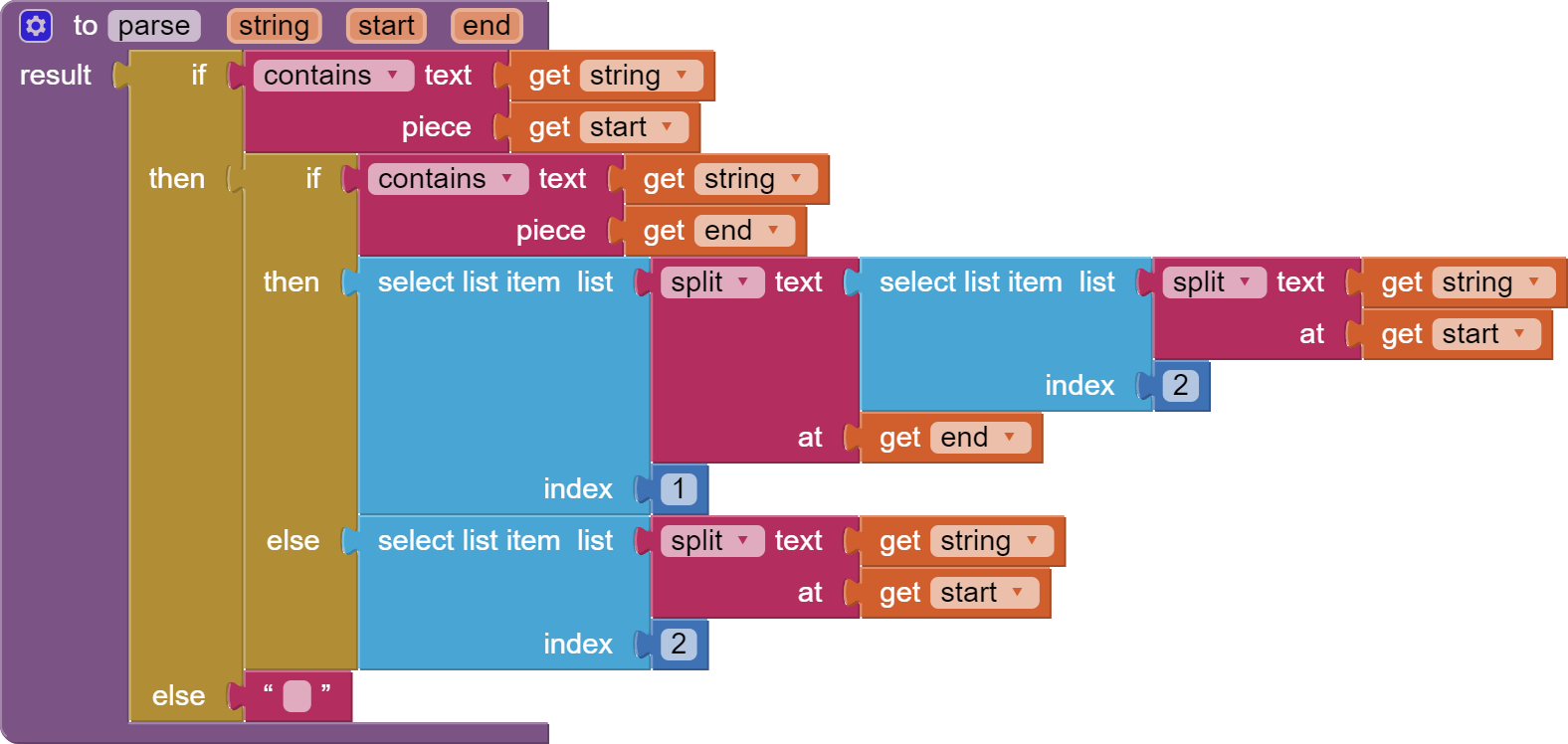
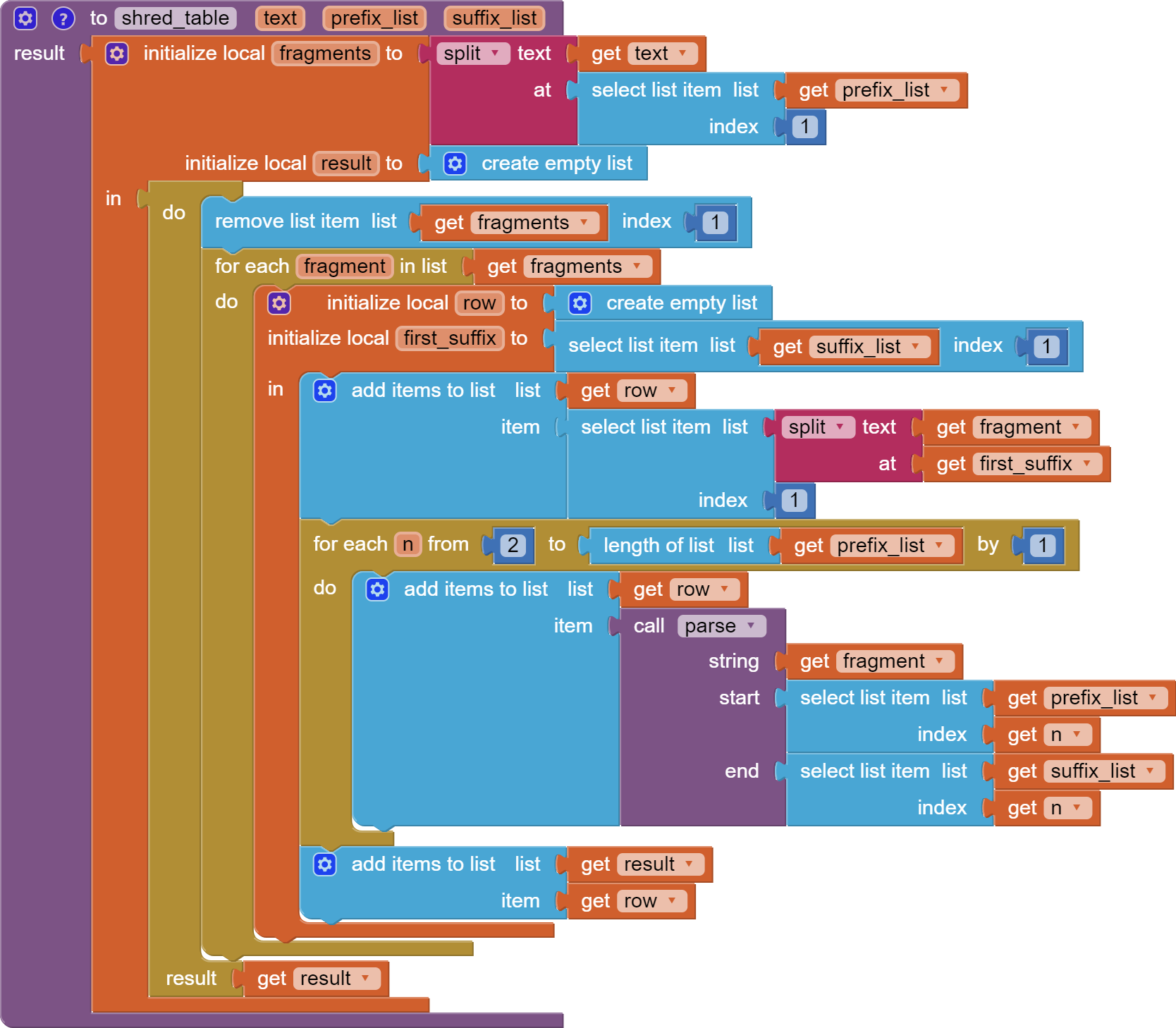
To code your own parser, the Text functions are required but I think they lack a few tools needed in this case. If anyone can think of a way to process the file successfully, it would be @ABG. Abraham is very good at making the impossible possible.
Also, the data does not really lend itself to a list format, would possibly work better as a Table (use version 4):