1-Introduction
The Xreg extension only contains two methods but covers 95% of Java functionality on regular expression.
What does it do more than the other two extensions that exist? It works for matches, capture groups, and any sort of replacement in string! See the following post:
[Regular Expression]
Both methods are designed simple enough to be integrated into App Inventor as on-chain blocks. See the same integration in AutoIt:
https://www.autoitscript.com/autoit3/docs/functions/StringRegExp.htm
Many sites have introductions to regular expressions, aimed at beginners.
The following page contains the exhaustive list of PCRE features:
https://www.pcre.org/original/doc/html/pcrepattern.html
2-Blocks Images
Check if a string fits a given regular expression pattern.
Replace text in a string based on regular expression pattern.
3-Documentation Regexp()
Regexp ( text:text, pattern:text, mode:int, start:int) : list
• text - The subject string to check
• pattern - The regular expression to match
• mode - A number to indicate how the function behaves.
1 - return data for FIRST match: [match1] if successful, else
2 - return data for ALL matchs: [match1, match2, ....] if successful, else
• start -The string position to start the match.
What are data for match?
- first character index of the match
- full match text
That's it if the model does not contain any captured groups.
If the model designer has requested the capture of numbered groups, the text of the groups is added to the list but not their position.
For one match, the data are:
- first character index of the match
- full match text
- text of capture group number 1
- text of capture group number 2
- etc...The programmer knows how many capture groups he has created in his pattern !
What is Error?
No error if start > length(string) : the function return [].
No error if start < 1 : the function assumes start=1.
No error if mode < 1 : the function assumes mode=1.
No error if mode > 1 : the function assumes mode=2.
Regardless of the mode, if the function fails, it returns the list:
[0, error message].
A frequent error comes from the regular expression, the error message indicates approximately the index of the syntax error in pattern.
4-Documentation RegexpReplace()
RegexpReplace(text:text, pattern:text, replacement:text, count:int): text
• text - The subject string to check
• pattern - The regular expression to match
• replacement - The text to replace the regular expression matching text with. To insert full match use $0 (or \0). To insert captured groups text, use $1,...,$9 (or \1,...,\9) as back-references.
• count - The number of times to execute the replacement in the string. Use 0 for global replacement.
Remarks
1-To separate back-reference replacements from actual (replaced) numbers, wrap them with curly braces, i.e: "${1}5".
2-If a "" needs to be in the replaced string it must be doubled. This is a consequence of the back-references mechanism.
3-The "" and "$" replacement formats are the only valid back-references formats supported.
5-Examples
#1: The search is case sensitive.
Searches for the three letters AND or ING but in uppercase. Since there is none in the text, the function returns the list: .

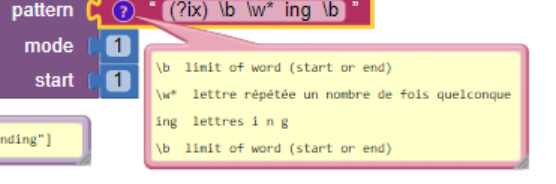
#2: The options (?i) et (?x)
Placed at the beginning of the pattern, the option (?i) makes the search case-insensitive. The (?x) option makes spaces insignificant.

#3: Using mode=1
We have a supposedly very long text and we are looking for FIRST words ending with "ing".
The result is list : [ index of FIRST match, text match].

#4: Using mode=2
We now want ALL the matches that result from the search.

#5: Using the start parameter

#6: Capture groups
In addition to the match also called full match, it is possible to recover match portions called groups.
They are delimited in the regular expression by parentheses. The first opening defines group 1, the second defines group 2, etc...

#7: Subpattern
Sometimes you need to group statements with parentheses without defining a capturing group.
For this we use (?: ... ).
Below we are looking for signed integers in a text.

#8: Comments in regular expression
The example below validates an entire string as a strong password.
The example also shows how a regular expression can be written using the (?x) option. The special character # begins a comment that extends to the end of the line.

The subpattern of the form (?=X) which appears several times in the pattern is called Positive Look-ahead: it is a test which is checked if the subpattern X matches from the current position. This test does not consume characters i.e. the current position is not modified in the text.
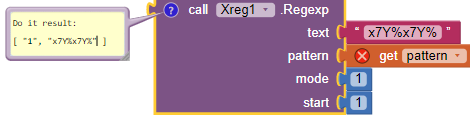
#9: Option DotAll
We consider the source text of a Java program and we look for block comments /* ....*/ to color them in green or to translate them or to delete them or ...
To do this, we use the dot "." which matches any character except (by default) a newline (CR, LF, CRLF). As our comments contain "new line" we remove this restriction with the option (?s) called DotAll.

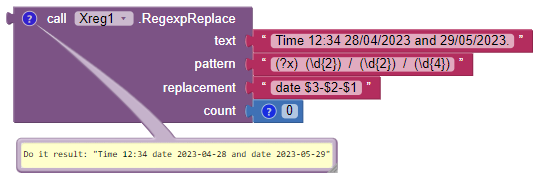
#10: Date format conversion.
In this example we convert the format "dd/mm/yyyy" to "yyyy-mm-dd" in all the text.
Since dd is the first captured group, it is referred to as $1, mm is the second captured group, it is referred to as $2 and yyyy is the third captureg group referred to $3.
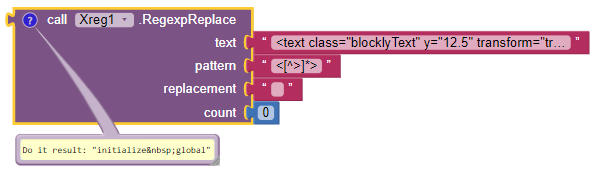
#11: Remove all tags from html text.
We search for < followed by any character except > repeated any number of times, followed by >. We replace match with the empty text.
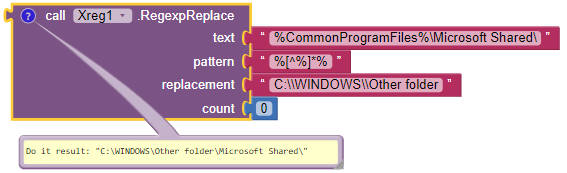
#12: The following example illustrates the need for a double backslash
As above we search for % followed by any character except % and repeated any number of times, and finally followed by %.
#13: RegexpReplace function limit
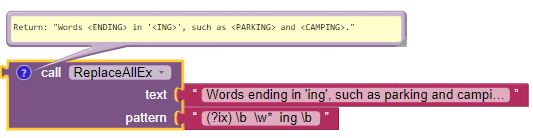
The RegexpReplace function recognizes the character pairs $0, $1,... in the replacement text, which makes it possible to treat 9 out of 10 cases. However, if you need a system function or a personal function to define the replacement text, RegexpReplace is faulty. This is because Java allows a Lambda expression as a parameter, while App Inventor does not.
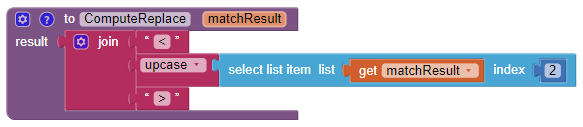
The example below proposes a reusable function ReplaceAllEx which uses the ComputeReplace function to be adapted to each case. It takes a matchResult list as an argument:
[iPos, fullMatch] or [iPos, fullMatch, group1, group2,....]
and returns the text that will replace fullMatch.

6-Download:
fr.danielm.Xreg.aix (6.6 KB)
The latest version 1.5 is here